
从一条日志消息的角度来巡览现代分布式系统。

混沌系统往往是不可预测的。在构建像分布式系统这样复杂的东西时,这一点尤其明显。如果不加以控制,这种不可预测性会无止境的浪费时间。因此,分布式系统的每个组件,无论多小,都必须设计成以简化的方式组合在一起。
Kubernetes 为抽象计算资源提供了一个很有前景的模型 —— 但即使是它也必须与其他分布式平台(如 Apache Kafka)协调一致,以确保可靠的数据传输。如果有人要整合这两个平台,它会如何运作?此外,如果你通过这样的系统跟踪像日志消息这么简单的东西,它会是什么样子?本文将重点介绍来自在 OKD 内运行的应用程序的日志消息如何通过 Kafka 进入数据仓库(OKD 是为 Red Hat OpenShift 提供支持的 Kubernetes 的原初社区发行版)。
OKD 定义的环境
这样的旅程始于 OKD,因为该容器平台完全覆盖了它抽象的硬件。这意味着日志消息等待由驻留在容器中的应用程序写入 stdout 或 stderr 流。从那里,日志消息被容器引擎(例如 CRI-O)重定向到节点的文件系统。
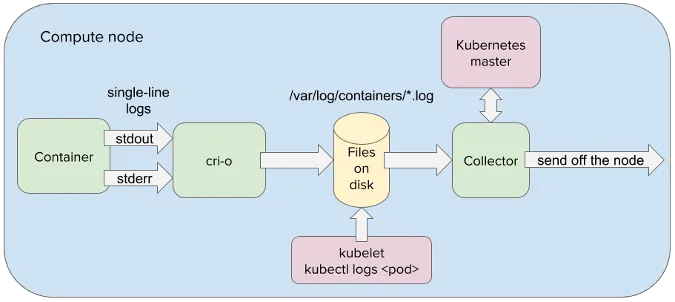
在 OpenShift 中,一个或多个容器封装在称为 pod(豆荚)的虚拟计算节点中。实际上,在 OKD 中运行的所有应用程序都被抽象为 pod。这允许应用程序以统一的方式操纵。这也大大简化了分布式组件之间的通信,因为 pod 可以通过 IP 地址和负载均衡服务进行系统寻址。因此,当日志消息由日志收集器应用程序从节点的文件系统获取时,它可以很容易地传递到在 OpenShift 中运行的另一个 pod 中。
在豆荚里的两个豌豆
为了确保可以在整个分布式系统中四处传播日志消息,日志收集器需要将日志消息传递到在 OpenShift 中运行的 Kafka 集群数据中心。通过 Kafka,日志消息可以以可靠且容错的方式低延迟传递给消费应用程序。但是,为了在 OKD 定义的环境中获得 Kafka 的好处,Kafka 需要完全集成到 OKD 中。
运行 Strimzi 操作子将所有 Kafka 组件实例化为 pod,并将它们集成在 OKD 环境中运行。 这包括用于排队日志消息的 Kafka 代理,用于从 Kafka 代理读取和写入的 Kafka 连接器,以及用于管理 Kafka 集群状态的 Zookeeper 节点。Strimzi 还可以将日志收集器实例化兼做 Kafka 连接器,允许日志收集器将日志消息直接提供给在 OKD 中运行的 Kafka 代理 pod。
在 OKD 内的 Kafka
当日志收集器 pod 将日志消息传递给 Kafka 代理时,收集器会写到单个代理分区,并将日志消息附加到该分区的末尾。使用 Kafka 的一个优点是它将日志收集器与日志的最终目标分离。由于解耦,日志收集器不关心日志最后是放在 Elasticsearch、Hadoop、Amazon S3 中的某个还是全都。Kafka 与所有基础设施连接良好,因此 Kafka 连接器可以在任何需要的地方获取日志消息。
一旦写入 Kafka 代理的分区,该日志消息就会在 Kafka 集群内的跨代理分区复制。这是它的一个非常强大的概念;结合平台的自愈功能,它创建了一个非常有弹性的分布式系统。例如,当节点变得不可用时,(故障)节点上运行的应用程序几乎立即在健康节点上生成。因此,即使带有 Kafka 代理的节点丢失或损坏,日志消息也能保证存活在尽可能多的节点上,并且新的 Kafka 代理将快速原位取代。
存储起来
在日志消息被提交到 Kafka 主题后,它将等待 Kafka 连接器使用它,该连接器将日志消息中继到分析引擎或日志记录仓库。在传递到其最终目的地时,可以分析日志消息以进行异常检测,也可以查询日志以立即进行根本原因分析,或用于其他目的。无论哪种方式,日志消息都由 Kafka 以安全可靠的方式传送到目的地。
OKD 和 Kafka 是正在迅速发展的功能强大的分布式平台。创建能够在不影响性能的情况下抽象出分布式计算的复杂特性的系统至关重要。毕竟,如果我们不能简化单一日志消息的旅程,我们怎么能夸耀全系统的效率呢?
via: https://opensource.com/article/18/9/life-log-message
作者:Josef Karásek 选题:lujun9972 译者:wxy 校对:wxy
发表回复