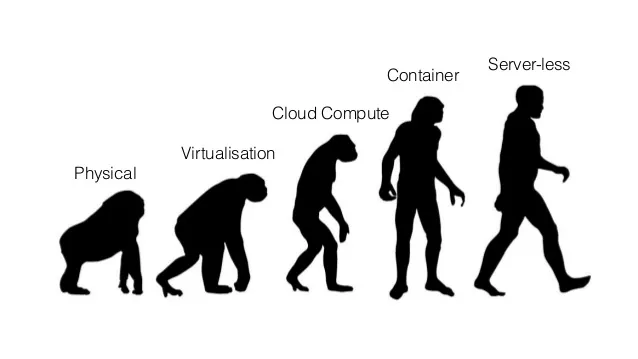
近来,在计算领域出现了很多关于 serverless 的讨论。serverless 是一个概念,它允许你提供代码或可执行程序给某个服务,由服务来为你执行它们,而你无需自己管理服务器。这就是所谓的 执行即服务 ,它带来了很多机会,同时也遇到了它独有的挑战。
简短回忆下计算领域的发展
早期,出现了……好吧,这有点复杂。很早的时候,出现了机械计算机,后来又有了埃尼阿克 ENIAC(Electronic Numerical Integrator And Computer,很早的电子计算机),但是都没有规模生产。直到大型机出现后,计算领域才快速发展。
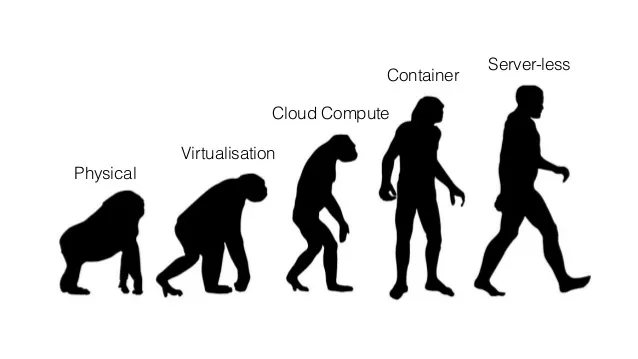
- 上世纪 50 年代 – 大型机
- 上世纪 60 年代 – 微型机
- 1994 – 机架服务器
- 2001 – 刀片服务器
- 本世纪初 – 虚拟服务器
- 2006 – 服务器云化
- 2013 – 容器化
- 2014 – serverless(计算资源服务化)
这些日期是大概的发布或者流行日期,无需和我争论时间的准确性。
计算领域的演进趋势是执行的功能单元越来越小。每一次演进通常都意味着运维负担的减小和运维灵活性的增加。
发展前景
喔,Serverless!但是,serverless 能给我们带来什么好处? 我们将面临什么挑战呢?
未执行代码时无需付费。我认为,这是个巨大的卖点。当无人访问你的站点或用你的 API 时,你无需付钱。没有持续支出的基础设施成本,仅仅支付你需要的部分。换句话说,这履行了云计算的承诺:“仅仅支付你真正用的资源”。
无需维护服务器,也无需考虑服务器安全。服务器的维护和安全将由你的服务提供商来处理(当然,你也可以架设自己的 serverless 主机,只是这似乎是在向错误的方向前进)。由于你的执行时间也是受限的,安全补丁也被简化了,因为完全不需要重启。这些都应该由你的服务提供商无缝地处理。
无限的可扩展性。这是又一个大的好处。假设你又开发了一个 Pokemon Go, 与其频繁地把站点下线维护升级,不如用 serverless 来不断地扩展。当然,这也是个双刃剑,大量的账单也会随之而来。如果你的业务的利润强依赖于站点上线率的话,serverless 确实能帮上忙。
强制的微服务架构。这也有两面性,一方面,微服务似乎是一种好的构建灵活可扩展的、容错的架构的方式。另一方面,如果你的业务没有按照这种方式设计,你将很难在已有的架构中引入 serverless。
但是现在你被限制在他们的平台上
受限的环境。你只能用服务提供商提供的环境,你想在 Rust 中用 serverless?你可能不会太幸运。
受限的预装包。你只有提供商预装的包。但是你或许能够提供你自己的包。
受限的执行时间。你的 Function 只可以运行这么长时间。如果你必须处理 1TB 的文件,你可能需要有一个解决办法或者用其他方案。
强制的微服务架构。参考上面的描述。
受限的监视和诊断能力。例如,你的代码在干什么? 在 serverless 中,基本不可能在调试器中设置断点和跟踪流程。你仍然可以像往常一样记录日志并发出统计度量,但是这带来的帮助很有限,无法定位在 serverless 环境中发生的难点问题。
竞争领域
自从 2014 年出现 AWS Lambda 以后,serverless 的提供商已经增加了一些。下面是一些主流的服务提供商:
- AWS Lambda – 起步最早的
- OpenWhisk – 在 IBM 的 Bluemix 云上可用
- Google Cloud Functions
- Azure Functions
这些平台都有它们的相对优势和劣势(例如,Azure 支持 C#,或者紧密集成在其他提供商的平台上)。这里面最大的玩家是 AWS。
通过 AWS 的 Lambda 和 API Gateway 构建你的第一个 API
我们来试一试 serverless。我们将用 AWS Lambda 和 API Gateway 来构建一个能返回 Jimmy 所说的“Guru Meditations”的 API。
所有代码在 GitHub 上可以找到。
API文档:
POST /
{
"status": "success",
"meditation": "did u mention banana cognac shower"
}
怎样组织工程文件
文件结构树:
.
├── LICENSE
├── README.md
├── server
│ ├── __init__.py
│ ├── meditate.py
│ └── swagger.json
├── setup.py
├── tests
│ └── test_server
│ └── test_meditate.py
└── tools
├── deploy.py
├── serve.py
├── serve.sh
├── setup.sh
└── zip.sh
AWS 中的信息(想了解这里究竟在做什么的详细信息,可查看源码 tools/deploy.py)。
- API。实际构建的对象。它在 AWS 中表示为一个单独的对象。
- 执行角色。在 AWS 中,每个 Function 作为一个单独的角色执行。在这里就是 meditations。
- 角色策略。每个 Function 作为一个角色执行,每个角色需要权限来干活。我们的 Lambda Function 不干太多活,故我们只添加一些日志记录权限。
- Lambda Function。运行我们的代码的地方。
- Swagger。 Swagger 是 API 的规范。API Gateway 支持解析 swagger 的定义来为 API 配置大部分资源。
- 部署。API Gateway 提供部署的概念。我们只需要为我们的 API 用一个就行(例如,所有的都用生产或者 yolo等),但是得知道它们是存在的,并且对于真正的产品级服务,你可能想用开发和暂存环境。
- 监控。在我们的业务崩溃的情况下(或者因为使用产生大量账单时),我们想以云告警查看方式为这些错误和费用添加一些监控。注意你应该修改
tools/deploy.py来正确地设置你的 email。
代码
Lambda Function 将从一个硬编码列表中随机选择一个并返回 guru meditations,非常简单:
import logging
import random
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def handler(event, context):
logger.info(u"received request with id '{}'".format(context.aws_request_id))
meditations = [
"off to a regex/",
"the count of machines abides",
"you wouldn't fax a bat",
"HAZARDOUS CHEMICALS + RKELLY",
"your solution requires a blood eagle",
"testing is broken because I'm lazy",
"did u mention banana cognac shower",
]
meditation = random.choice(meditations)
return {
"status": "success",
"meditation": meditation,
}
deploy.py 脚本
这个脚本相当长,我没法贴在这里。它基本只是遍历上述“AWS 中的信息”下的项目,确保每项都存在。
我们来部署这个脚本
只需运行 ./tools/deploy.py。
基本完成了。不过似乎在权限申请上有些问题,由于 API Gateway 没有权限去执行你的 Function,所以你的 Lambda Function 将不能执行,报错应该是“Execution failed due to configuration error: Invalid permissions on Lambda function”。我不知道怎么用 botocore 添加权限。你可以通过 AWS console 来解决这个问题,找到你的 API, 进到 /POST 端点,进到“integration request”,点击“Lambda Function”旁边的编辑图标,修改它,然后保存。此时将弹出一个窗口提示“You are about to give API Gateway permission to invoke your Lambda function”, 点击“OK”。
当你完成后,记录下 ./tools/deploy.py 打印出的 URL,像下面这样调用它,然后查看你的新 API 的行为:
$ curl -X POST https://a1b2c3d4.execute-api.us-east-1.amazonaws.com/prod/
{"status": "success", "meditation": "the count of machines abides"}
本地运行
不幸的是,AWS Lambda 没有好的方法能在本地运行你的代码。在这个例子里,我们将用一个简单的 flask 服务器来在本地托管合适的端点,并调用 handler 函数。
from __future__ import absolute_import
from flask import Flask, jsonify
from server.meditate import handler
app = Flask(__name__)
@app.route("/", methods=["POST"])
def index():
class FakeContext(object):
aws_request_id = "XXX"
return jsonify(**handler(None, FakeContext()))
app.run(host="0.0.0.0")
你可以在仓库中用 ./tools/serve.sh 运行它,像这样调用:
$ curl -X POST http://localhost:5000/
{
"meditation": "your solution requires a blood eagle",
"status": "success"
}
测试
你总是应该测试你的代码。我们的测试方法是导入并运行我们的 handler 函数。这是最基本的 python 测试方法:
from __future__ import absolute_import
import unittest
from server.meditate import handler
class SubmitTestCase(unittest.TestCase):
def test_submit(self):
class FakeContext(object):
aws_request_id = "XXX"
response = handler(None, FakeContext())
self.assertEquals(response["status"], "success")
self.assertTrue("meditation" in response)
你可以在仓库里通过 nose2 运行这个测试代码。
更多前景
- 和 AWS 服务的无缝集成。通过 boto,你可以完美地轻易连接到任何其他的 AWS 服务。你可以轻易地让你的执行角色用 IAM 访问这些服务。你可以从 S3 取文件或放文件到 S3,连接到 Dynamo DB,调用其他 Lambda Function,等等。
- 访问数据库。你也可以轻易地访问远程数据库。在你的 Lambda handler 模块的最上面连接数据库,并在handler 函数中执行查询。你很可能必须从它的安装位置上传相关的包内容才能使它正常工作。可能你也需要静态编译某些库。
- 调用其他 webservices。API Gateway 也是一种把 webservices 的输出从一个格式转换成另一个格式的方法。你可以充分利用这个特点通过不同的 webservices 来代理调用,或者当业务变更时提供后向兼容能力。
via: http://blog.ryankelly.us/2016/08/07/going-serverless-with-aws-lambda-and-api-gateway.html
作者:Ryan Kelly 译者:messon007 校对:wxy
发表回复