可以很公平地说,JavaScript 是当下软件工程中最重要的技术。对于那些深入接触过编程语言、编译器和虚拟机的人来说,这仍然有点令人惊讶,因为在语言设计者们看来,JavaScript 不是十分优雅;在编译器工程师们看来,它没有多少可优化的地方;甚至还没有一个伟大的标准库。这取决于你和谁吐槽,JavaScript 的缺点你花上数周都枚举不完,而你总会找到一些你从所未知的奇怪的东西。尽管这看起来明显困难重重,不过 JavaScript 还是成为了当今 web 的核心,并且还(通过 Node.js)成为服务器端和云端的主导技术,甚至还开辟了进军物联网领域的道路。
那么问题来了,为什么 JavaScript 如此受欢迎?或者说如此成功?我知道没有一个很好的答案。如今我们有许多使用 JavaScript 的好理由,或许最重要的是围绕其构建的庞大的生态系统,以及现今大量可用的资源。但所有这一切实际上是发展到一定程度的后果。为什么 JavaScript 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 JavaScript。回顾过去,似乎第一波 JavaScript 浪潮爆发在上个年代的后半段。那个时候 JavaScript 引擎加速了各种不同的任务的执行,很自然的,这可能让很多人对 JavaScript 刮目相看。
回到过去那些日子,这些加速使用了现在所谓的传统 JavaScript 基准进行测试——从苹果的 SunSpider 基准(JavaScript 微基准之母)到 Mozilla 的 Kraken 基准 和谷歌的 V8 基准。后来,V8 基准被 Octane 基准 取代,而苹果发布了新的 JetStream 基准。这些传统的 JavaScript 基准测试驱动了无数人的努力,使 JavaScript 的性能达到了本世纪初没人能预料到的水平。据报道其性能加速达到了 1000 倍,一夜之间在网站使用 <script> 标签不再是与魔鬼共舞,做客户端不再仅仅是可能的了,甚至是被鼓励的。
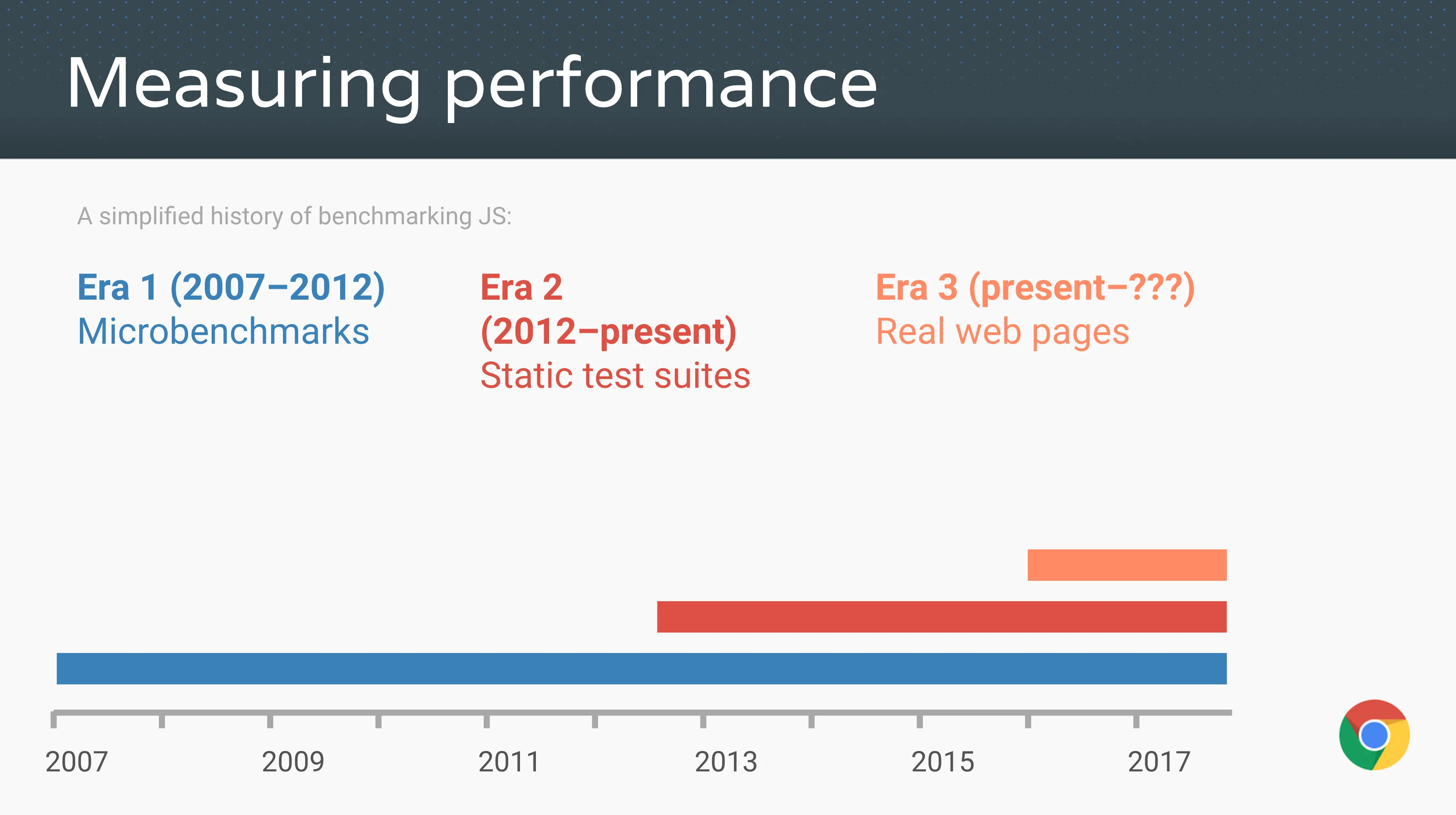
(来源: Advanced JS performance with V8 and Web Assembly, Chrome Developer Summit 2016, @s3ththompson。)
现在是 2016 年,所有(相关的)JavaScript 引擎的性能都达到了一个令人难以置信的水平,web 应用像原生应用一样快(或者能够像原生应用一样快)。引擎配有复杂的优化编译器,通过收集之前的关于类型/形状的反馈来推测某些操作(例如属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数优化是由 SunSpider 或 Kraken 等微基准以及 Octane 和 JetStream 等静态测试套件驱动的。由于有像 asm.js 和 Emscripten 这样的 JavaScript 技术,我们甚至可以将大型 C++ 应用程序编译成 JavaScript,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 AngryBots,无需沙盒,而过去的 web 游戏需要安装一堆诸如 Adobe Flash 或 Chrome PNaCl 的特殊插件。
这些成就绝大多数都要归功于这些微基准和静态性能测试套件的出现,以及与这些传统的 JavaScript 基准间的竞争的结果。你可以对 SunSpider 表示不满,但很显然,没有 SunSpider,JavaScript 的性能可能达不到今天的高度。好吧,赞美到此为止。现在看看另一方面,所有的静态性能测试——无论是 微基准 还是大型应用的 宏基准 ,都注定要随着时间的推移变成噩梦!为什么?因为在开始摆弄它之前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般适用性将呈指数级下降。例如,我们将 Octane 作为现实世界中 web 应用性能的代表,并且在相当长的一段时间里,它可能做得很不错,但是现在,Octane 与现实场景中的时间分布是截然不同的,因此即使眼下再优化 Octane 乃至超越自身,可能在现实世界中还是得不到任何显著的改进(无论是通用 web 还是 Node.js 的工作负载)。
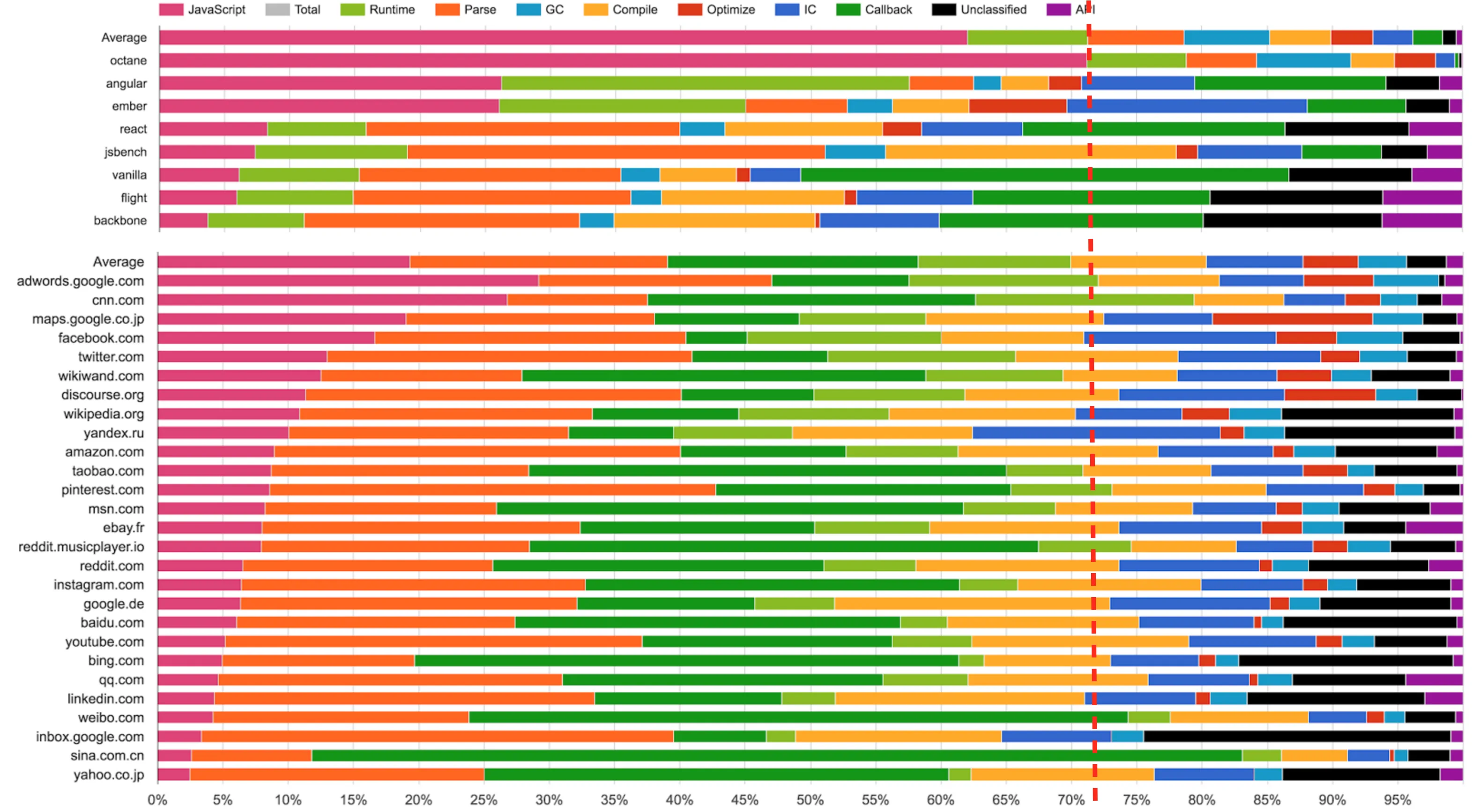
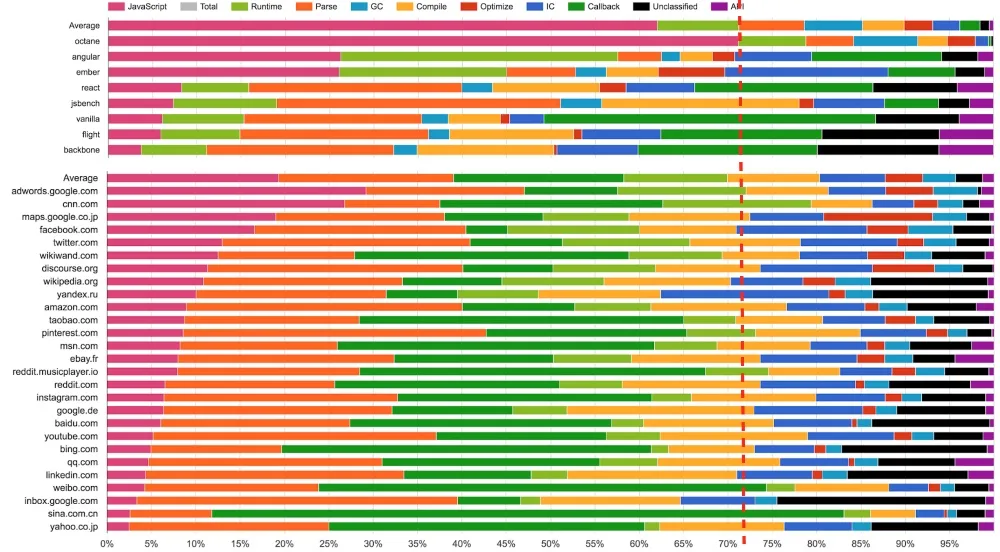
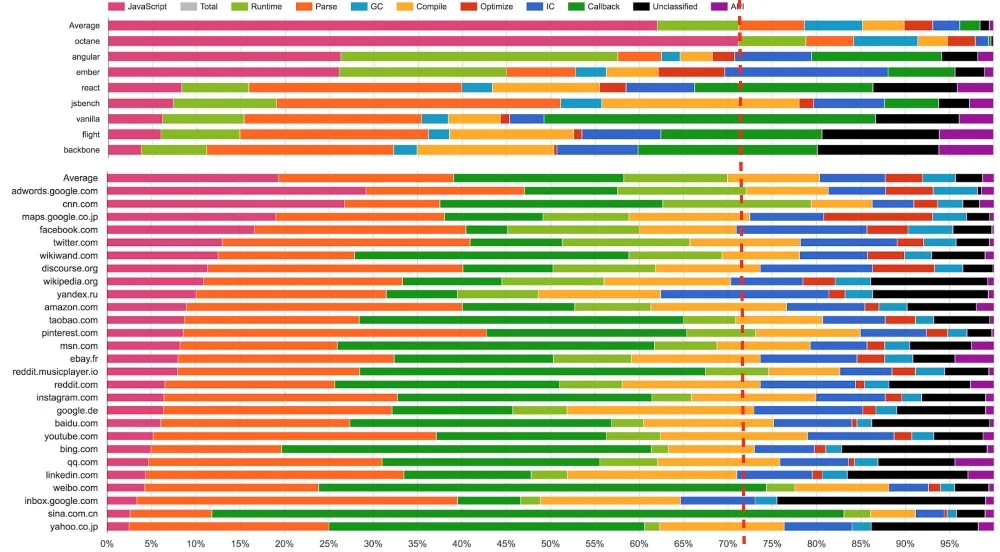
(来源:Real-World JavaScript Performance,BlinkOn 6 conference,@tverwaes)
由于传统 JavaScript 基准(包括最新版的 JetStream 和 Octane)可能已经背离其有用性变得越来越远,我们开始在 2016 年初寻找新的方法来测量现实场景的性能,为 V8 和 Chrome 添加了大量新的性能追踪钩子。我们还特意添加一些机制来查看我们在浏览 web 时的时间究竟开销在哪里,例如,是脚本执行、垃圾回收、编译,还是什么地方?而这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 Octane 花费了 70% 以上的时间去执行 JavaScript 和垃圾回收,而浏览 web 的时候,通常执行 JavaScript 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。在 Octane 中并没有体现出它花费了大量时间来解析和编译。因此,将更多的时间用在优化 JavaScript 执行上将提高你的 Octane 跑分,但不会对加载 youtube.com 有任何积极的影响。事实上,花费更多的时间来优化 JavaScript 执行甚至可能有损你现实场景的性能,因为编译器需要更多的时间,或者你需要跟踪更多的反馈,最终在编译、垃圾回收和 运行时桶 等方面开销了更多的时间。
还有另外一组基准测试用于测量浏览器整体性能(包括 JavaScript 和 DOM 性能),最新推出的是 Speedometer 基准。该基准试图通过运行一个用不同的主流 web 框架实现的简单的 TodoMVC 应用(现在看来有点过时了,不过新版本正在研发中)以捕获更真实的现实场景的性能。上述幻灯片中的各种测试 (Angular、Ember、React、Vanilla、Flight 和 Backbone)挨着放在 Octane 之后,你可以看到,此时此刻这些测试似乎更好地代表了现实世界的性能指标。但是请注意,这些数据收集在本文撰写将近 6 个月以前,而且我们优化了更多的现实场景模式(例如我们正在重构垃圾回收系统以显著地降低开销,并且 解析器也正在重新设计)。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不能很好的代表现实场景中 Node.js 应用性能。
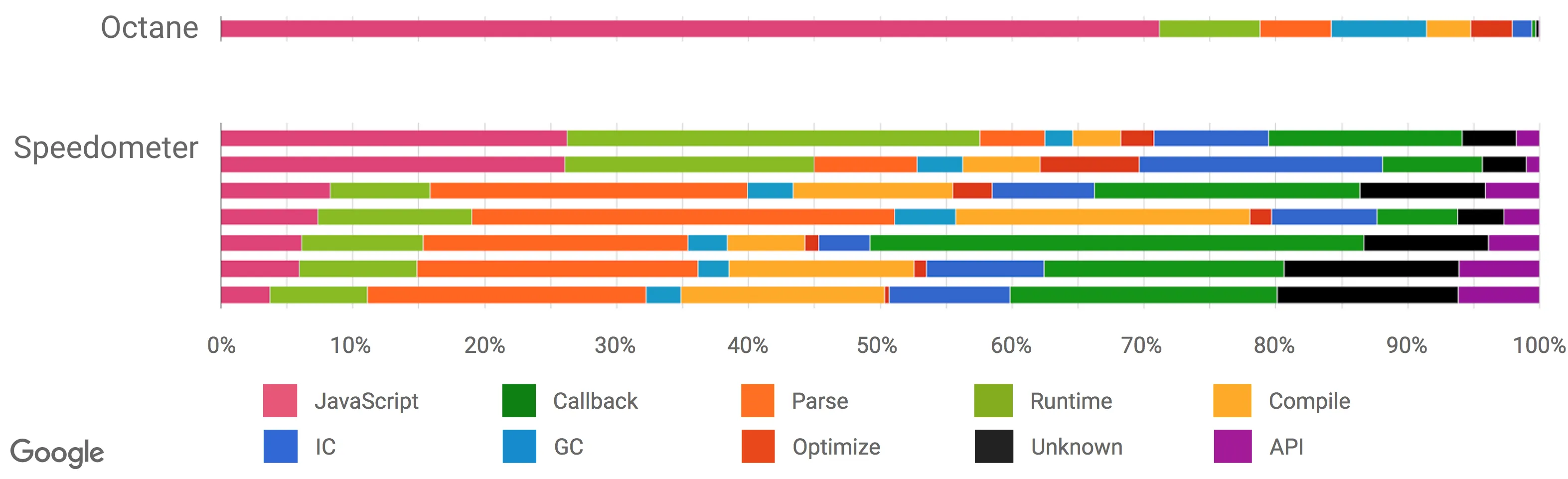
(来源: Real-World JavaScript Performance, BlinkOn 6 conference, @tverwaes.)
所有这一切可能已经路人皆知了,因此我将用本文剩下的部分强调一些具体案例,它们对关于我为什么认为这不仅有用,而且必须停止关注某一阈值的静态峰值性能基准测试对于 JavaScript 社区的健康是很关键的。让我通过一些例子说明 JavaScript 引擎怎样来玩弄基准的。
臭名昭著的 SunSpider 案例
一篇关于传统 JavaScript 基准测试的博客如果没有指出 SunSpider 那个明显的问题是不完整的。让我们从性能测试的最佳实践开始,它在现实场景中不是很适用:bitops-bitwise-and.js 性能测试。
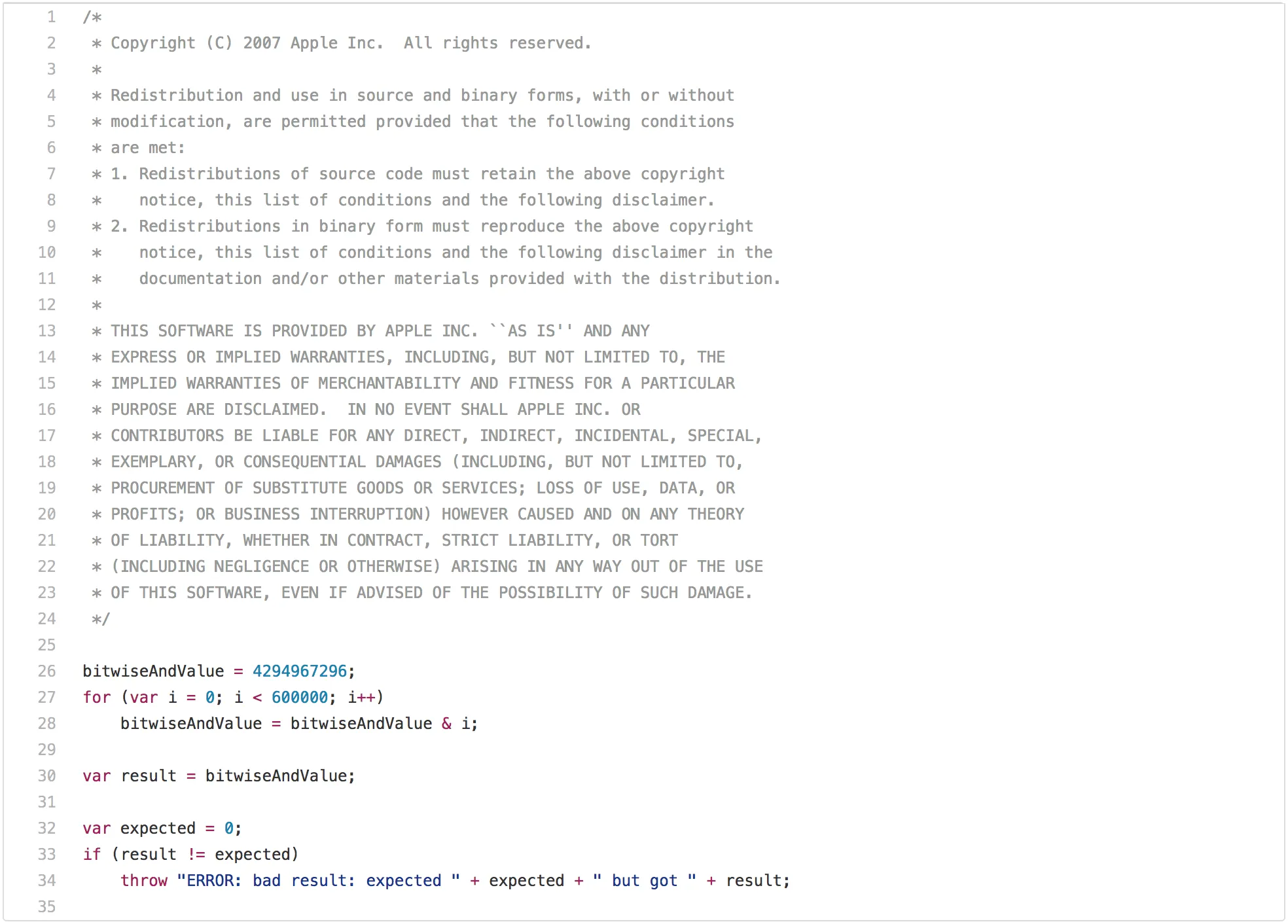
有一些算法需要进行快速的 AND 位运算,特别是从 C/C++ 转译成 JavaScript 的地方,所以快速执行该操作确实有点意义。然而,现实场景中的网页可能不关心引擎在循环中执行 AND 位运算是否比另一个引擎快两倍。但是再盯着这段代码几秒钟后,你可能会注意到在第一次循环迭代之后 bitwiseAndValue 将变成 0,并且在接下来的 599999 次迭代中将保持为 0。所以一旦你让此获得了好的性能,比如在差不多的硬件上所有测试均低于 5ms,在经过尝试之后你会意识到,只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 loop peeling 后面的死代码),那你现在就可以开始玩弄这个基准测试了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 bitwiseAndValue 是全局对象的常规属性还是在执行脚本之前不存在,全局对象或者它的原型上必须没有拦截器。但如果你真的想要赢得这个基准测试,并且你愿意全力以赴,那么你可以在不到 1ms 的时间内完成这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
好吧,那么 bitops-bitwise-and.js 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更逼真的场景——string-tagcloud.js 测试,它基本上是运行一个较早版本的 json.js polyfill。该测试可以说看起来比位运算测试更合理,但是花点时间查看基准的配置之后立刻会发现:大量的时间浪费在一条 eval 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
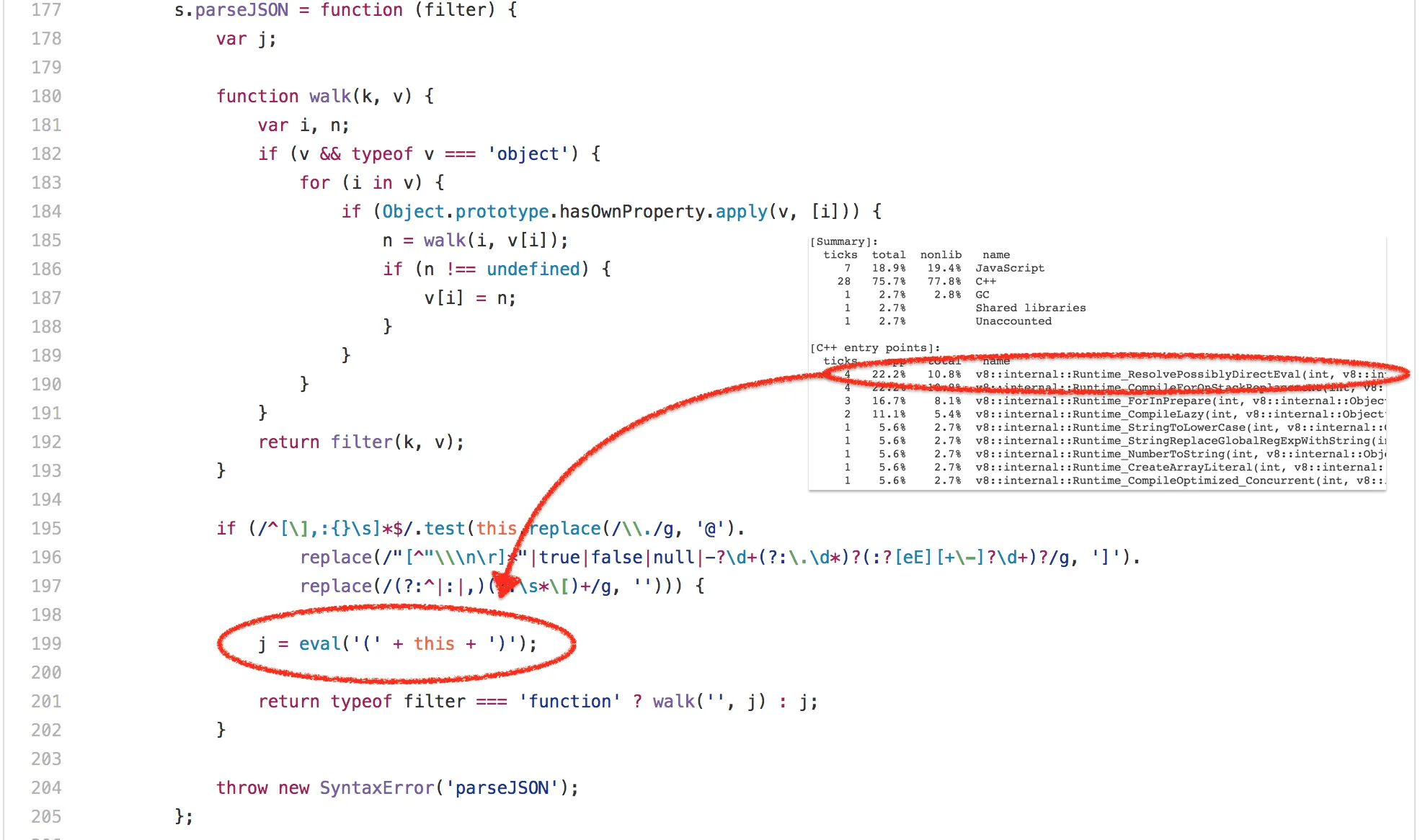
仔细看看,这个 eval 只执行了一次,并传递一个 JSON 格式的字符串,它包含一个由 2501 个含有 tag 和 popularity 属性的对象组成的数组:
([
{
"tag": "titillation",
"popularity": 4294967296
},
{
"tag": "foamless",
"popularity": 1257718401
},
{
"tag": "snarler",
"popularity": 613166183
},
{
"tag": "multangularness",
"popularity": 368304452任何
},
{
"tag": "Fesapo unventurous",
"popularity": 248026512
},
{
"tag": "esthesioblast",
"popularity": 179556755
},
{
"tag": "echeneidoid",
"popularity": 136641578
},
{
"tag": "embryoctony",
"popularity": 107852576
},
...
])
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 JSON 并生成适当的对象图的开销将更加低廉。所以,加快这个基准测试的一个小把戏就是模拟 eval,并尝试总是将数据首先作为 JSON 解析,如果以 JSON 方式读取失败,才回退进行真实的解析、编译、执行(尽管需要一些额外的黑魔法来跳过括号)。早在 2007 年,这甚至不算是一个坏点子,因为没有 JSON.parse,不过在 2017 年这只是 JavaScript 引擎的技术债,可能会让 eval 的合法使用遥遥无期。
audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
+++ audio-oscillator.js 2016-12-15 22:02:26.397326067 +0100
@@ -1931,6 +1931,10 @@
var frequency = 344.53;
var sine = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+var unused = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+unused.waveTableLength = 1024;
+unused.generate();
+
var calcOsc = function() {
sine.generate();
将原始的 audio-oscillator.js 执行时间与包含额外未使用的 Oscillator 实例与修改的 waveTableLength 的版本进行比较,显示的是预期的结果:
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
Time (audio-oscillator-once): 64 ms.
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
Time (audio-oscillator-once): 81 ms.
$
这是一个非常可怕的性能悬崖的例子:假设开发人员编写代码库,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户读过了性能说明开始使用该库,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即特定的 BinaryOpIC 的某种污染方式的类型反馈,并且遭受 20% 的减速(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是随机的。
现在这种情况在 JavaScript 领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 JavaScript 的性能是基于乐观的假设和猜测。我们已经花了 大量 时间和精力来试图找到避免这些性能悬崖的方法,而仍提供了(几乎)相同的性能。事实证明,尽可能避免 idiv 是很有意义的,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 TurboFan 的做法有异于 Crankshaft 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化右手侧的(未知的) 2 的冥看起来像这样(伪代码):
if 0 < rhs then
msk = rhs - 1
if rhs & msk != 0 then
lhs % rhs
else
if lhs < 0 then
-(-lhs & msk)
else
lhs & msk
else
if rhs < -1 then
lhs % rhs
else
zero
这产生更加一致和可预测的性能(使用 TurboFan):
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
Time (audio-oscillator-once): 69 ms.
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
Time (audio-oscillator-once): 69 ms.
$
基准和过度特定化的问题在于基准可以给你提示可以看看哪里以及该怎么做,但它不告诉你应该做到什么程度,不能保护合理优化。例如,所有 JavaScript 引擎都使用基准来防止性能回退,但是运行 Kraken 不能保护我们在 TurboFan 中使用的常规方法,即我们可以将 TurboFan 中的模优化降级到过度特定的版本的 Crankshaft,而基准不会告诉我们性能回退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不能任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度特定化将支配一切,你会有一个真正的、非常好的可接受的性能,以及巨大的性能悬崖线。
Kraken 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 JavaScript 基准测试—— Octane 测试。
深入接触 Octane
Octane 基准是 V8 基准的继承者,最初由谷歌于 2012 年中期发布,目前的版本 Octane 2.0 于 2013 年年底发布。这个版本包含 15 个独立测试,其中对于 Splay 和 Mandreel,我们用来测试吞吐量和延迟。这些测试范围从 微软 TypeScript 编译器 编译自身到 zlib 测试测量原生的 asm.js 性能,再到 RegExp 引擎的性能测试、光线追踪器、2D 物理引擎等。有关各个基准测试项的详细概述,请参阅说明书。所有这些测试项目都经过仔细的筛选,以反映 JavaScript 性能的方方面面,我们认为这在 2012 年非常重要,或许预计在不久的将来会变得更加重要。
在很大程度上 Octane 在实现其将 JavaScript 性能提高到更高水平的目标方面无比的成功,它在 2012 年和 2013 年引导了良性的竞争,Octane 创造了巨大的业绩和成就。但是现在将近 2017 年了,世界看起来与 2012 年真的迥然不同了。除了通常和经常被引用的批评,Octane 中的大多数项目基本上已经过时(例如,老版本的 TypeScript,zlib 通过老版本的 Emscripten 编译而成,Mandreel 甚至不再可用等等),某种更重要的方式影响了 Octane 的用途:
我们看到大型 web 框架赢得了 web 种族之争,尤其是像 Ember 和 AngularJS 这样的重型框架,它们使用了 JavaScript 执行模式,不过根本没有被 Octane 所反映,并且经常受到(我们)Octane 具体优化的损害。我们还看到 JavaScript 在服务器和工具前端获胜,这意味着有大规模的 JavaScript 应用现在通常运行上数星期,如果不是运行上数年都不会被 Octane 捕获。正如开篇所述,我们有硬数据表明 Octane 的执行和内存配置文件与我们每天在 web 上看到的截然不同。
让我们来看看今天一些玩弄 Octane 基准的具体例子,其中优化不再反映在现实场景。请注意,即使这可能听起来有点负面回顾,它绝对不意味着这样!正如我已经说过好几遍,Octane 是 JavaScript 性能故事中的重要一章,它发挥了至关重要的作用。在过去由 Octane 驱动的 JavaScript 引擎中的所有优化都是善意地添加的,因为 Octane 是现实场景性能的好代理!每个年代都有它的基准,而对于每一个基准都有一段时间你必须要放手!
话虽如此,让我们在路上看这个节目,首先看看 Box2D 测试,它是基于 Box2DWeb (一个最初由 Erin Catto 编写的移植到 JavaScript 的流行的 2D 物理引擎)的。总的来说,很多浮点数学驱动了很多 JavaScript 引擎下很好的优化,但是,事实证明它包含一个可以肆意玩弄基准的漏洞(怪我,我发现了漏洞,并添加在这种情况下的漏洞)。在基准中有一个函数 D.prototype.UpdatePairs,看起来像这样:
D.prototype.UpdatePairs = function(b) {
var e = this;
var f = e.m_pairCount = 0,
m;
for (f = 0; f < e.m_moveBuffer.length; ++f) {
m = e.m_moveBuffer[f];
var r = e.m_tree.GetFatAABB(m);
e.m_tree.Query(function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
},
r)
}
for (f = e.m_moveBuffer.length = 0; f < e.m_pairCount;) {
r = e.m_pairBuffer[f];
var s = e.m_tree.GetUserData(r.proxyA),
v = e.m_tree.GetUserData(r.proxyB);
b(s, v);
for (++f; f < e.m_pairCount;) {
s = e.m_pairBuffer[f];
if (s.proxyA != r.proxyA || s.proxyB != r.proxyB) break;
++f
}
}
};
一些分析显示,在第一个循环中传递给 e.m_tree.Query 的无辜的内部函数花费了大量的时间:
function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
}
更准确地说,时间并不是开销在这个函数本身,而是由此触发的操作和内置库函数。结果,我们花费了基准调用的总体执行时间的 4-7% 在 Compare` 运行时函数上,它实现了抽象关系比较的一般情况。
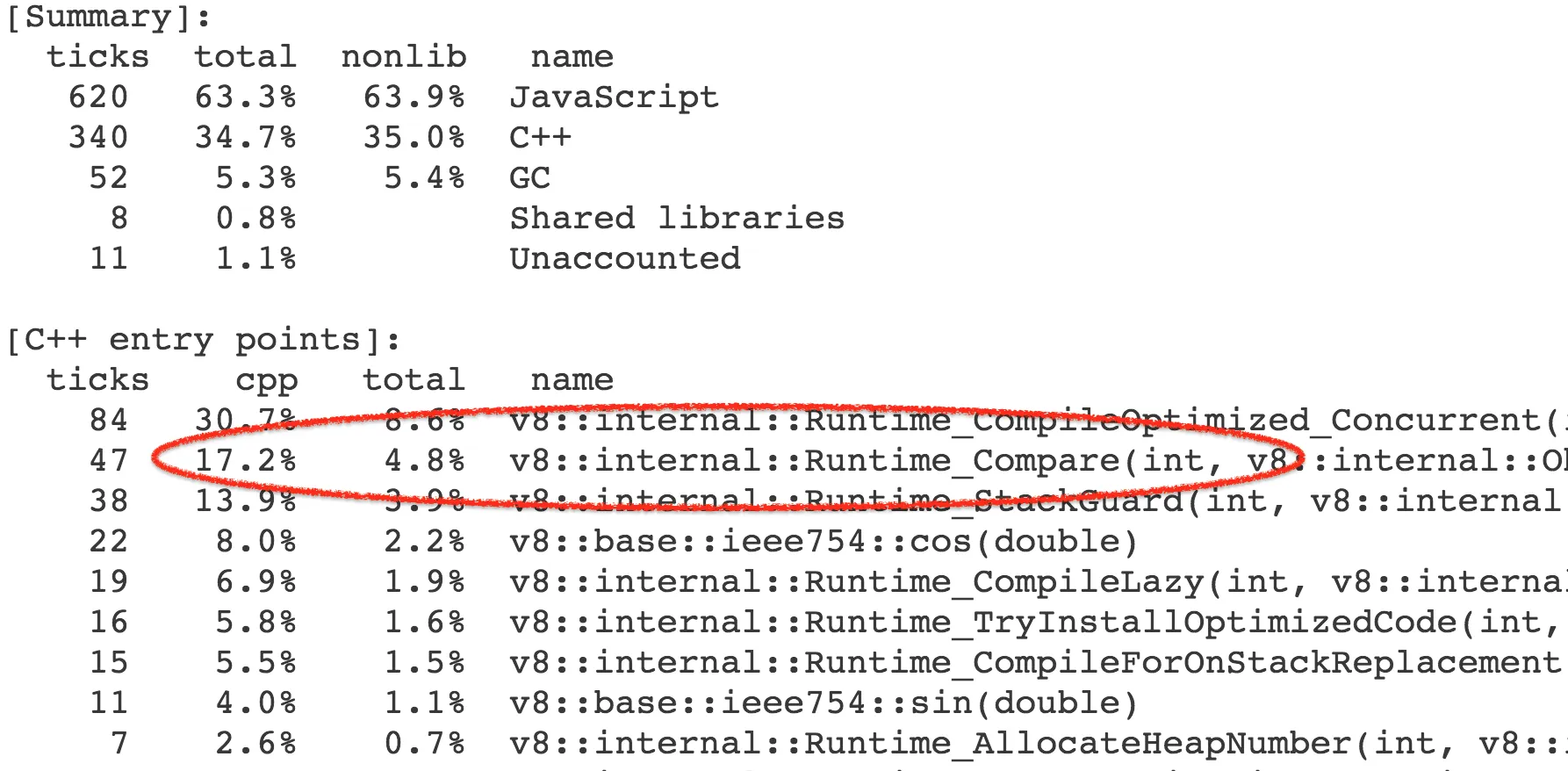
几乎所有对运行时函数的调用都来自 CompareICStub,它用于内部函数中的两个关系比较:
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 JavaScript 中的许多东西一样,抽象关系比较 的直观用法不一定是正确的。在这个函数中,t 和 m 都是 L 的实例,它是这个应用的一个中心类,但不会覆盖 Symbol.toPrimitive、“toString”、“valueOf” 或 Symbol.toStringTag 属性,它们与抽象关系比较相关。所以如果你写 t < m 会发生什么呢?
- 调用 ToPrimitive(
t,hint Number)。 - 运行 OrdinaryToPrimitive(
t,"number"),因为这里没有Symbol.toPrimitive。 - 执行
t.valueOf(),这会获得t自身的值,因为它调用了默认的 Object.prototype.valueOf。 - 接着执行
t.toString(),这会生成"[object Object]",因为调用了默认的 Object.prototype.toString,并且没有找到L的 Symbol.toStringTag。 - 调用 ToPrimitive(
m,hint Number)。 - 运行 OrdinaryToPrimitive(
m,"number"),因为这里没有Symbol.toPrimitive。 - 执行
m.valueOf(),这会获得m自身的值,因为它调用了默认的 Object.prototype.valueOf。 - 接着执行
m.toString(),这会生成"[object Object]",因为调用了默认的 Object.prototype.toString,并且没有找到L的 Symbol.toStringTag。 - 执行比较
"[object Object]" < "[object Object]",结果是false。
至于 t >= m 亦复如是,它总会输出 true。所以这里是一个漏洞——使用抽象关系比较这种方法没有意义。而利用它的方法是使编译器常数折叠,即给基准打补丁:
作者简介:
我是 Benedikt Meurer,住在 Ottobrunn(德国巴伐利亚州慕尼黑东南部的一个市镇)的一名软件工程师。我于 2007 年在锡根大学获得应用计算机科学与电气工程的文凭,打那以后的 5 年里我在编译器和软件分析领域担任研究员(2007 至 2008 年间还研究过微系统设计)。2013 年我加入了谷歌的慕尼黑办公室,我的工作目标主要是 V8 JavaScript 引擎,目前是 JavaScript 执行性能优化团队的一名技术领导。
---
via: <http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks>
作者:[Benedikt Meurer](http://benediktmeurer.de/) 译者:[OneNewLife](https://github.com/OneNewLife) 校对:[OneNewLife](https://github.com/OneNewLife), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
发表回复