

Python 配备了几种内置数据类型来帮我们组织数据。这些结构包括列表、字典、元组和集合。
根据 Python 3 文档:
集合是一个无序集合,没有重复元素。基本用途包括成员测试和消除重复的条目。集合对象还支持数学运算,如并集、交集、差集和对等差分。
在本文中,我们将回顾并查看上述定义中列出的每个要素的示例。让我们马上开始,看看如何创建它。
初始化一个集合
有两种方法可以创建一个集合:一个是给内置函数 set() 提供一个元素列表,另一个是使用花括号 {}。
使用内置函数 set() 来初始化一个集合:
>>> s1 = set([1, 2, 3])
>>> s1
{1, 2, 3}
>>> type(s1)
<class 'set'>
使用 {}:
>>> s2 = {3, 4, 5}
>>> s2
{3, 4, 5}
>>> type(s2)
<class 'set'>
>>>
如你所见,这两种方法都是有效的。但问题是,如果我们想要一个空的集合呢?
>>> s = {}
>>> type(s)
<class 'dict'>
没错,如果我们使用空花括号,我们将得到一个字典而不是一个集合。=)
值得一提的是,为了简单起见,本文中提供的所有示例都将使用整数集合,但集合可以包含 Python 支持的所有 可哈希的 数据类型。换句话说,即整数、字符串和元组,而不是列表或字典这样的可变类型。
>>> s = {1, 'coffee', [4, 'python']}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
既然你知道了如何创建一个集合以及它可以包含哪些类型的元素,那么让我们继续看看为什么我们总是应该把它放在我们的工具箱中。
为什么你需要使用它
写代码时,你可以用不止一种方法来完成它。有些被认为是相当糟糕的,另一些则是清晰的、简洁的和可维护的,或者是 “ Python 式的 ”。
当一个经验丰富的 Python 开发人员( Python 人 )调用一些不够 “ Python 式的 ” 的代码时,他们通常认为着这些代码不遵循通用指南,并且无法被认为是以一种好的方式(可读性)来表达意图。
让我们开始探索 Python 集合那些不仅可以帮助我们提高可读性,还可以加快程序执行时间的方式。
无序的集合元素
首先你需要明白的是:你无法使用索引访问集合中的元素。
>>> s = {1, 2, 3}
>>> s[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing
或者使用切片修改它们:
>>> s[0:2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object is not subscriptable
但是,如果我们需要删除重复项,或者进行组合列表(与)之类的数学运算,那么我们可以,并且应该始终使用集合。
我不得不提一下,在迭代时,集合的表现优于列表。所以,如果你需要它,那就加深对它的喜爱吧。为什么?好吧,这篇文章并不打算解释集合的内部工作原理,但是如果你感兴趣的话,这里有几个链接,你可以阅读它:
没有重复项
写这篇文章的时候,我总是不停地思考,我经常使用 for 循环和 if 语句检查并删除列表中的重复元素。记得那时我的脸红了,而且不止一次,我写了类似这样的代码:
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = []
>>> for item in my_list:
... if item not in no_duplicate_list:
... no_duplicate_list.append(item)
...
>>> no_duplicate_list
[1, 2, 3, 4]
或者使用列表解析:
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = []
>>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list]
[None, None, None, None]
>>> no_duplicate_list
[1, 2, 3, 4]
但没关系,因为我们现在有了武器装备,没有什么比这更重要的了:
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = list(set(my_list))
>>> no_duplicate_list
[1, 2, 3, 4]
>>>
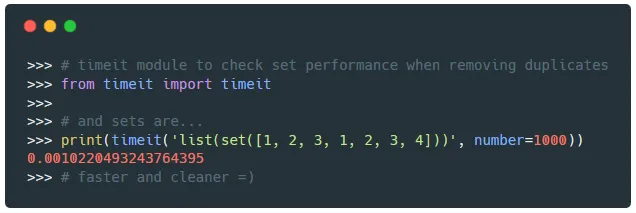
现在让我们使用 timeit 模块,查看列表和集合在删除重复项时的执行时间:
>>> from timeit import timeit
>>> def no_duplicates(list):
... no_duplicate_list = []
... [no_duplicate_list.append(item) for item in list if item not in no_duplicate_list]
... return no_duplicate_list
...
>>> # 首先,让我们看看列表的执行情况:
>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
0.0018683355819786227
>>> from timeit import timeit
>>> # 使用集合:
>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
0.0010220493243764395
>>> # 快速而且干净 =)
使用集合而不是列表推导不仅让我们编写更少的代码,而且还能让我们获得更具可读性和高性能的代码。
注意:请记住集合是无序的,因此无法保证在将它们转换回列表时,元素的顺序不变。
优美胜于丑陋
明了胜于晦涩
简洁胜于复杂
扁平胜于嵌套
集合不正是这样美丽、明了、简单且扁平吗?
成员测试
每次我们使用 if 语句来检查一个元素,例如,它是否在列表中时,意味着你正在进行成员测试:
my_list = [1, 2, 3]
>>> if 2 in my_list:
... print('Yes, this is a membership test!')
...
Yes, this is a membership test!
在执行这些操作时,集合比列表更高效:
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = list(range(1000))",
... number=1000)
12.459663048726043
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = set(range(1000))",
... number=1000)
.12354438152988223
注意:上面的测试来自于这个 StackOverflow 话题。
因此,如果你在巨大的列表中进行这样的比较,尝试将该列表转换为集合,它应该可以加快你的速度。
如何使用
现在你已经了解了集合是什么以及为什么你应该使用它,现在让我们快速浏览一下,看看我们如何修改和操作它。
添加元素
根据要添加的元素数量,我们要在 add() 和 update() 方法之间进行选择。
add() 适用于添加单个元素:
>>> s = {1, 2, 3}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
update() 适用于添加多个元素:
>>> s = {1, 2, 3}
>>> s.update([2, 3, 4, 5, 6])
>>> s
{1, 2, 3, 4, 5, 6}
请记住,集合会移除重复项。
移除元素
如果你希望在代码中尝试删除不在集合中的元素时收到警报,请使用 remove()。否则,discard() 提供了一个很好的选择:
>>> s = {1, 2, 3}
>>> s.remove(3)
>>> s
{1, 2}
>>> s.remove(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 3
discard() 不会引起任何错误:
>>> s = {1, 2, 3}
>>> s.discard(3)
>>> s
{1, 2}
>>> s.discard(3)
>>> # 什么都不会发生
我们也可以使用 pop() 来随机丢弃一个元素:
>>> s = {1, 2, 3, 4, 5}
>>> s.pop() # 删除一个任意的元素
1
>>> s
{2, 3, 4, 5}
或者 clear() 方法来清空一个集合:
>>> s = {1, 2, 3, 4, 5}
>>> s.clear() # 清空集合
>>> s
set()
union()
union() 或者 | 将创建一个新集合,其中包含我们提供集合中的所有元素:
>>> s1 = {1, 2, 3}
>>> s2 = {3, 4, 5}
>>> s1.union(s2) # 或者 's1 | s2'
{1, 2, 3, 4, 5}
intersection()
intersection 或 & 将返回一个由集合共同元素组成的集合:
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s3 = {3, 4, 5}
>>> s1.intersection(s2, s3) # 或者 's1 & s2 & s3'
{3}
difference()
使用 diference() 或 - 创建一个新集合,其值在 “s1” 中但不在 “s2” 中:
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.difference(s2) # 或者 's1 - s2'
{1}
symmetric_diference()
symetric_difference 或 ^ 将返回集合之间的不同元素。
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.symmetric_difference(s2) # 或者 's1 ^ s2'
{1, 4}
结论
我希望在阅读本文之后,你会知道集合是什么,如何操纵它的元素以及它可以执行的操作。知道何时使用集合无疑会帮助你编写更清晰的代码并加速你的程序。
如果你有任何疑问,请发表评论,我很乐意尝试回答。另外,不要忘记,如果你已经理解了集合,它们在 Python Cheatsheet 中有自己的一席之地,在那里你可以快速参考并重新认知你已经知道的内容。
via: https://www.pythoncheatsheet.org/blog/python-sets-what-why-how
作者:wilfredinni 译者:MjSeven 校对:wxy
发表回复