
在前面的文章中,我展示了 Sed 命令的基本用法, Sed 是一个实用的流编辑器。今天,我们准备去了解关于 Sed 更多的知识,深入了解 Sed 的运行模式。这将是你全面了解 Sed 命令的一个机会,深入挖掘它的运行细节和精妙之处。因此,如果你已经做好了准备,那就打开终端吧,下载测试文件 然后坐在电脑前:开始我们的探索之旅吧!

关于 Sed 的一点点理论知识
首先我们看一下 sed 的运行模式
要准确理解 Sed 命令,你必须先了解工具的运行模式。
当处理数据时,Sed 从输入源一次读入一行,并将它保存到所谓的 模式空间 中。所有 Sed 的变换都发生在模式空间。变换都是由命令行上或外部 Sed 脚本文件提供的单字母命令来描述的。大多数 Sed 命令都可以由一个地址或一个地址范围作为前导来限制它们的作用范围。
默认情况下,Sed 在结束每个处理循环后输出模式空间中的内容,也就是说,输出发生在输入的下一个行覆盖模式空间之前。我们可以将这种运行模式总结如下:
- 尝试将下一个行读入到模式空间中
- 如果读取成功:
- 按脚本中的顺序将所有命令应用到与那个地址匹配的当前输入行上
- 如果 sed 没有以静默模式(
-n)运行,那么将输出模式空间中的所有内容(可能会是修改过的)。 - 重新回到 1。
因此,在每个行被处理完毕之后,模式空间中的内容将被丢弃,它并不适合长时间保存内容。基于这种目的,Sed 有第二个缓冲区: 保持空间 。除非你显式地要求它将数据置入到保持空间、或从保持空间中取得数据,否则 Sed 从不清除保持空间的内容。在我们后面学习到 exchange、get、hold 命令时将深入研究它。
Sed 的抽象机制
你将在许多的 Sed 教程中都会看到上面解释的模式。的确,这是充分正确理解大多数基本 Sed 程序所必需的。但是当你深入研究更多的高级命令时,你将会发现,仅这些知识还是不够的。因此,我们现在尝试去了解更深入的一些知识。
的确,Sed 可以被视为是抽象机制的实现,它的状态由三个缓冲区 、两个寄存器和两个标志来定义的:
- 三个缓冲区用于去保存任意长度的文本。是的,是三个!在前面的基本运行模式中我们谈到了两个:模式空间和保持空间,但是 Sed 还有第三个缓冲区: 追加队列 。从 Sed 脚本的角度来看,它是一个只写缓冲区,Sed 将在它运行时的预定义阶段来自动刷新它(一般是在从输入源读入一个新行之前,或仅在它退出运行之前)。
- Sed 也维护两个寄存器: 行计数器 (LC)用于保存从输入源读取的行数,而 程序计数器 (PC)总是用来保存下一个将要运行的命令的索引(就是脚本中的位置),Sed 将它作为它的主循环的一部分来自动增加 PC。但在使用特定的命令时,脚本也可以直接修改 PC 去跳过或重复执行程序的一部分。这就像使用 Sed 实现的一个循环或条件语句。更多内容将在下面的专用分支一节中描述。
- 最后,两个标志可以修改某些 Sed 命令的行为: 自动输出 (AP)标志和<ruby替换 substitution(SF)标志。当自动输出标志 AP 被设置时,Sed 将在模式空间的内容被覆盖前自动输出(尤其是,包括但不限于,在从输入源读入一个新行之前)。当自动输出标志被清除时(即:没有设置),Sed 在脚本中没有显式命令的情况下,将不会输出模式空间中的内容。你可以通过在“静默模式”(使用命令行选项
-n或者在第一行或脚本中使用特殊注释#n)运行 Sed 命令来清除自动输出标志。当它的地址和查找模式与模式空间中的内容都匹配时,替换标志 SF 将被替换命令(s命令)设置。替换标志在每个新的循环开始时、或当从输入源读入一个新行时、或获得条件分支之后将被清除。我们将在分支一节中详细研究这一话题。
另外,Sed 维护一个进入到它的地址范围(关于地址范围的更多知识将在地址范围一节详细描述)的命令列表,以及用于读取和写入数据的两个文件句柄(你将在读取和写入命令的描述中获得更多有关文件句柄的内容)。
一个更精确的 Sed 运行模式
一图胜千言,所以我画了一个流程图去描述 Sed 的运行模式。我将两个东西放在了旁边,像处理多个输入文件或错误处理,但是我认为这足够你去理解任何 Sed 程序的行为了,并且可以避免你在编写你自己的 Sed 脚本时浪费在摸索上的时间。
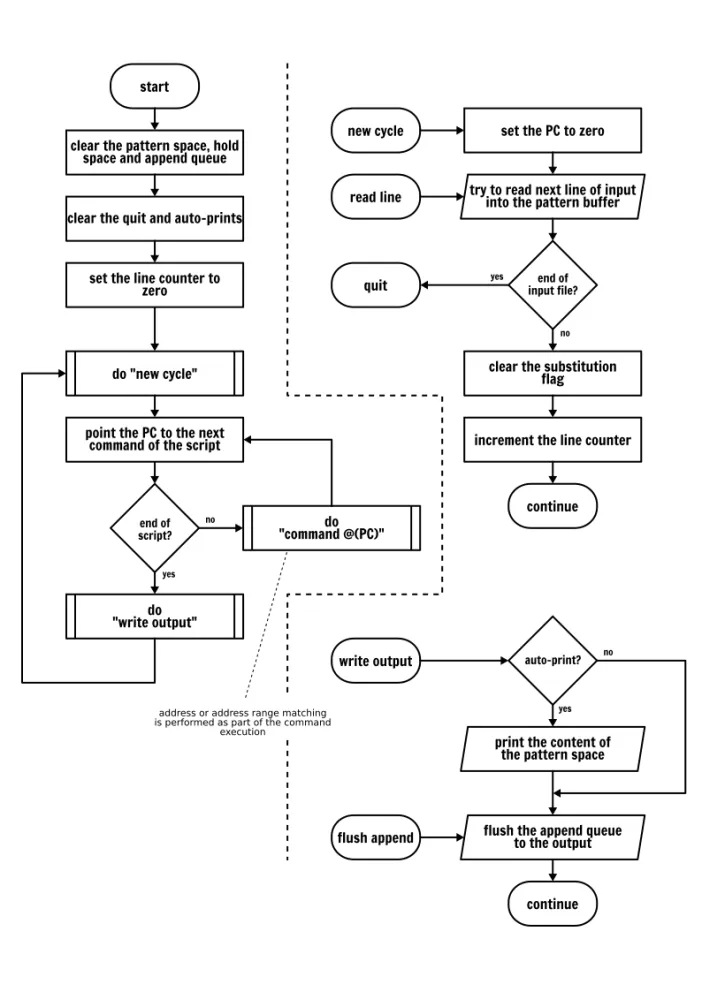
你可能已经注意到,在上面的流程图上我并没有描述特定的命令动作。对于命令,我们将逐个详细讲解。因此,不用着急,我们马上开始!
打印命令
打印命令(p)是用于输出在它运行那一刻模式空间中的内容。它并不会以任何方式改变 Sed 抽象机制中的状态。
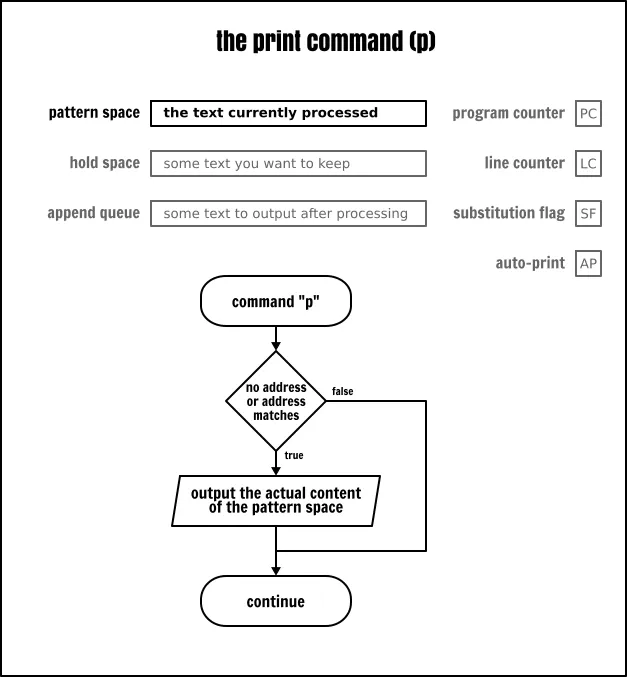
示例:
sed -e 'p' inputfile上面的命令将输出输入文件中每一行的内容……两次,因为你一旦显式地要求使用 p 命令时,将会在每个处理循环结束时再隐式地输出一次(因为在这里我们不是在“静默模式”中运行 Sed)。
如果我们不想每个行看到两次,我们可以用两种方式去解决它:
sed -n -e 'p' inputfile # 在静默模式中显式输出
sed -e '' inputfile # 空的“什么都不做的”程序,隐式输出注意:-e 选项是引入一个 Sed 命令。它被用于区分命令和文件名。由于一个 Sed 表达式必须包含至少一个命令,所以对于第一个命令,-e 标志不是必需的。但是,由于我个人使用习惯问题,为了与在这里的大多数的一个命令行上给出多个 Sed 表达式的更复杂的案例保持一致性,我添加了它。你自己去判断这是一个好习惯还是坏习惯,并且在本文的后面部分还将延用这一习惯。
地址
显而易见,print 命令本身并没有太多的用处。但是,如果你在它之前添加一个地址,这样它就只输出输入文件的一些行,这样它就突然变得能够从一个输入文件中过滤一些不希望的行。那么 Sed 的地址又是什么呢?它是如何来辨别输入文件的“行”呢?
行号
Sed 的地址既可以是一个行号($ 表示“最后一行”)也可以是一个正则表达式。在使用行号时,你需要记住 Sed 中的行数是从 1 开始的 —— 并且需要注意的是,它不是从 0 行开始的。
sed -n -e '1p' inputfile # 仅输出文件的第一行
sed -n -e '5p' inputfile # 仅输出第 5 行
sed -n -e '$p' inputfile # 输出文件的最后一行
sed -n -e '0p' inputfile # 结果将是报错,因为 0 不是有效的行号根据 POSIX 规范,如果你指定了几个输出文件,那么它的行号是累加的。换句话说,当 Sed 打开一个新输入文件时,它的行计数器是不会被重置的。因此,以下的两个命令所做的事情是一样的。仅输出一行文本:
sed -n -e '1p' inputfile1 inputfile2 inputfile3
cat inputfile1 inputfile2 inputfile3 | sed -n -e '1p'实际上,确实在 POSIX 中规定了多个文件是如何处理的:
如果指定了多个文件,将按指定的文件命名顺序进行读取并被串联编辑。
但是,一些 Sed 的实现提供了命令行选项去改变这种行为,比如, GNU Sed 的 -s 标志(在使用 GNU Sed -i 标志时,它也被隐式地应用):
sed -sn -e '1p' inputfile1 inputfile2 inputfile3如果你的 Sed 实现支持这种非标准选项,那么关于它的具体细节请查看 man 手册页。
正则表达式
我前面说过,Sed 地址既可以是行号也可以是正则表达式。那么正则表达式是什么呢?
正如它的名字,一个正则表达式是描述一个字符串集合的方法。如果一个指定的字符串符合一个正则表达式所描述的集合,那么我们就认为这个字符串与正则表达式匹配。
正则表达式可以包含必须完全匹配的文本字符。例如,所有的字母和数字,以及大部分可以打印的字符。但是,一些符号有特定意义:
- 它们相当于锚,像
^和$它们分别表示一个行的开始和结束; - 能够做为整个字符集的占位符的其它符号(比如圆点
.可以匹配任意单个字符,或者方括号[]用于定义一个自定义的字符集); - 另外的是表示重复出现的数量(像 克莱尼星号(
*) 表示前面的模式出现 0、1 或多次);
这篇文章的目的不是给大家讲正则表达式。因此,我只粘几个示例。但是,你可以在网络上随便找到很多关于正则表达式的教程,正则表达式的功能非常强大,它可用于许多标准的 Unix 命令和编程语言中,并且是每个 Unix 用户应该掌握的技能。
下面是使用 Sed 地址的几个示例:
sed -n -e '/systemd/p' inputfile # 仅输出包含字符串“systemd”的行
sed -n -e '/nologin$/p' inputfile # 仅输出以“nologin”结尾的行
sed -n -e '/^bin/p' inputfile # 仅输出以“bin”开头的行
sed -n -e '/^$/p' inputfile # 仅输出空行(即:开始和结束之间什么都没有的行)
sed -n -e '/./p' inputfile # 仅输出包含字符的行(即:非空行)
sed -n -e '/^.$/p' inputfile # 仅输出只包含一个字符的行
sed -n -e '/admin.*false/p' inputfile # 仅输出包含字符串“admin”后面有字符串“false”的行(在它们之间有任意数量的任意字符)
sed -n -e '/1[0,3]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”或“3”的行
sed -n -e '/1[0-2]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”、“1”、“2”或“3”的行
sed -n -e '/1.*2/p' inputfile # 仅输出包含字符“1”后面是一个“2”(在它们之间有任意数量的字符)的行
sed -n -e '/1[0-9]*2/p' inputfile # 仅输出包含字符“1”后面跟着“0”、“1”、或更多数字,最后面是一个“2”的行如果你想在正则表达式(包括正则表达式分隔符)中去除字符的特殊意义,你可以在它前面使用一个反斜杠:
# 输出所有包含字符串“/usr/sbin/nologin”的行
sed -ne '//usr/sbin/nologin/p' inputfile并不限制你只能使用斜杠作为地址中正则表达式的分隔符。你可以通过在第一个分隔符前面加上反斜杠()的方式,来使用任何你认为适合你需要和偏好的其它字符作为正则表达式的分隔符。当你用地址与带文件路径的字符一起来匹配的时,是非常有用的:
# 以下两个命令是完全相同的
sed -ne '//usr/sbin/nologin/p' inputfile
sed -ne '=/usr/sbin/nologin=p' inputfile扩展的正则表达式
默认情况下,Sed 的正则表达式引擎仅理解 POSIX 基本正则表达式 的语法。如果你需要用到 扩展正则表达式,你必须在 Sed 命令上添加 -E 标志。扩展正则表达式在基本正则表达式基础上增加了一组额外的特性,并且很多都是很重要的,它们所要求的反斜杠要少很多。我们来比较一下:
sed -n -e '/(www)|(mail)/p' inputfile
sed -En -e '/(www)|(mail)/p' inputfile花括号量词
正则表达式之所以强大的一个原因是范围量词 {,}。事实上,当你写一个不太精确匹配的正则表达式时,量词 * 就是一个非常完美的符号。但是,(用花括号量词)你可以显式在它边上添加一个下限和上限,这样就有了很好的灵活性。当量词范围的下限省略时,下限被假定为 0。当上限被省略时,上限被假定为无限大:
| 括号 | 速记词 | 解释 |
| | –/ inputfile`
s命令和它的参数是用任意一个字符来分隔的。这主要看你的习惯,在 99% 的时间中我都使用斜杠,但也会用其它的字符:sed s%:%--X inputfile或者甚至是sed 's : --/1' inputfile、sed 's/:/--/3' inputfile、…- 如果你想执行一个全局替换(即:在模式空间上的每个非重叠匹配上进行),你需要增加
g标志:`sed ‘s/:/-
w temp
‘
现在,在流输出中专门用于插入一些文本的 Sed 命令清单结束了。我的最后一个示例纯属好玩,但是由于我前面提到过有一个写入命令,这个示例将我们完美地带到下一节,在下一节我们将看到在 Sed 中如何将数据写入到一个外部文件。
替代的输出
Sed 的设计思想是,所有的文本转换都将写入到进程的标准输出上。但是,Sed 也有一些特性支持将数据发送到替代的目的地。你有两种方式去实现上述的输出目标替换:使用专门的写入命令(w),或者在一个替换命令(s)上添加一个写入标志。
写入命令
写入命令(w)会追加模式空间的内容到给定的目标文件中。POSIX 要求在 Sed 处理任何数据之前,目标文件能够被 Sed 所创建。如果给定的目标文件已经存在,它将被覆写。
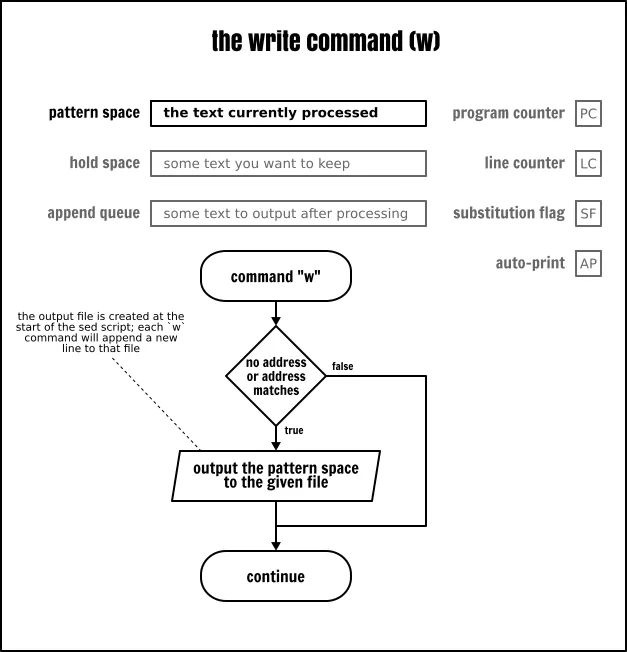
因此,即便是你从未真的写入到该文件中,但该文件仍然会被创建。例如,下列的 Sed 程序将创建/覆写这个 output 文件,那怕是这个写入命令从未被运行过:
echo | sed -ne '
q # 立刻退出
w output # 这个命令从未被运行
'你可以将几个写入命令指向到同一个目标文件。指向同一个目标文件的所有写入命令将追加那个文件的内容(工作方式几乎与 shell 的重定向符 >> 相同):
sed < inputfile -ne '
/:/bin/false$/w server
/:/usr/sbin/nologin$/w server
w output
'
cat server替换命令的写入标志
在前面,我们已经学习了替换命令(s),它有一个 p 选项用于在替换之后输出模式空间的内容。同样它也提供一个类似功能的 w 选项,用于在替换之后将模式空间的内容输出到一个文件中:
sed < inputfile -ne '
s/:.*/nologin$//w server
s/:.*/false$//w server
'
cat server注释
我无数次使用过它们,但我从未花时间正式介绍过它们,因此,我决定现在来正式地介绍它们:就像大多数编程语言一样,注释是添加软件不去解析的自由格式文本的一种方法。Sed 的语法很晦涩,我不得不强调在脚本中需要的地方添加足够的注释。否则,除了作者外其他人将几乎无法理解它。
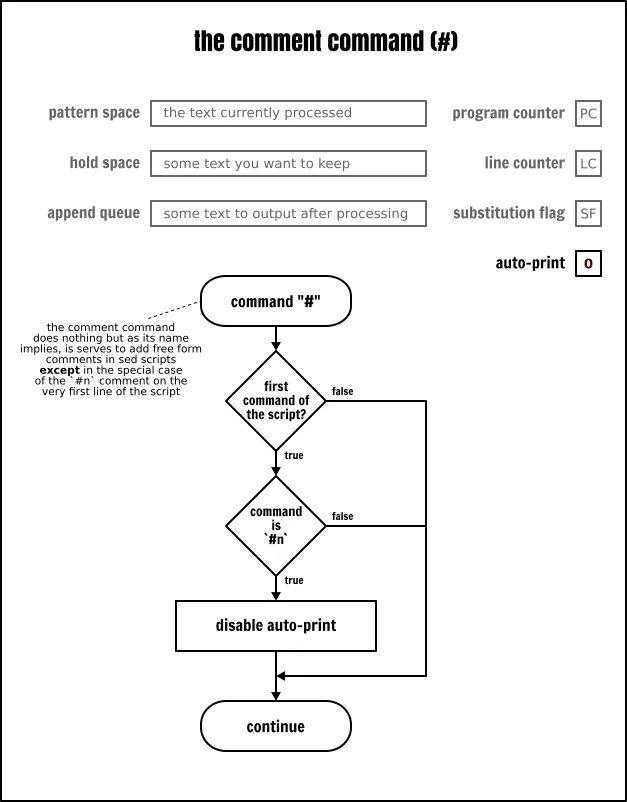
不过,和 Sed 的其它部分一样,注释也有它自己的微妙之处。首先并且是最重要的,注释并不是语法结构,但它是真正意义的 Sed 命令。注释虽然是一个“什么也不做”的命令,但它仍然是一个命令。至少,它是在 POSIX 中定义了的。因此,严格地说,它们只允许使用在其它命令允许使用的地方。
大多数 Sed 实现都通过允许行内命令来放松了那种要求,就像在那个文章中我到处都使用的那样。
结束那个主题之前,需要说一下 #n 注释(# 后面紧跟一个字母 n,中间没有空格)的特殊情况。如果在脚本的第一行找到这个精确注释,Sed 将切换到静默模式(即:清除自动输出标志),就像在命令行上指定了 -n 选项一样。
很少用得到的命令
现在,我们已经学习的命令能让你写出你所用到的 99.99% 的脚本。但是,如果我没有提到剩余的 Sed 命令,那么本教程就不能称为完全指南。我把它们留到最后是因为我们很少用到它。但或许你有实际使用案例,那么你就会发现它们很有用。如果是那样,请不要犹豫,在下面的评论区中把它分享给我们吧。
行数命令
这个 = 命令将向标准输出上显示当前 Sed 正在读取的行数,这个行数就是行计数器(LC)的内容。没有任何方式从任何一个 Sed 缓冲区中捕获那个数字,也不能对它进行输出格式化。由于这两个限制使得这个命令的可用性大大降低。
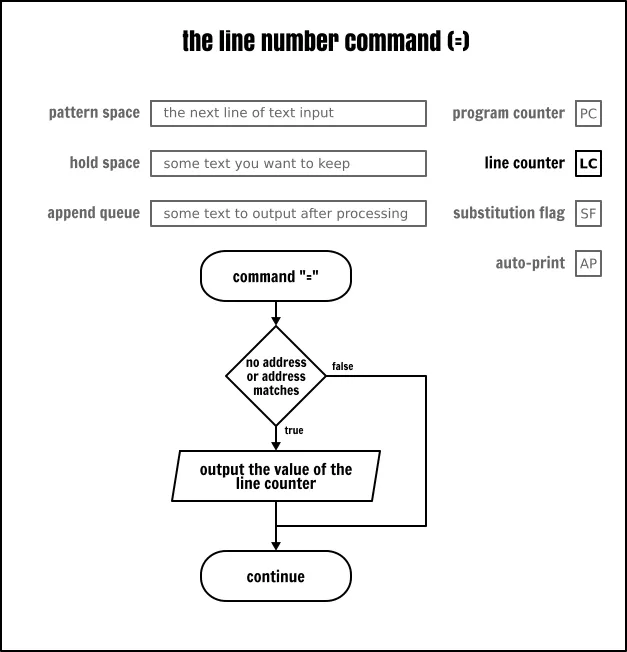
请记住,在严格的 POSIX 兼容模式中,当在命令行上给定几个输入文件时,Sed 并不重置那个计数器,而是连续地增长它,就像所有的输入文件是连接在一起的一样。一些 Sed 实现,像 GNU Sed,它就有一个选项可以在每个输入文件读取结束后去重置计数器。
明确打印命令
这个 l(小写的字母 l)作用类似于打印命令(p),但它是以精确的格式去输出模式空间的内容。以下引用自 POSIX 标准:
在 XBD 转义序列中列出的字符和相关的动作(
\、a、b、f、r、t、v)将被写为相应的转义序列;在那个表中的n是不适用的。不在那个表中的不可打印字符将被写为一个三位八进制数字(在前面使用一个反斜杠),表示字符中的每个字节(最重要的字节在前面)。长行应该被换行,通过写一个反斜杠后跟一个换行符来表示换行位置;发生换行时的长度是不确定的,但应该适合输出设备的具体情况。每个行应该以一个$标记结束。
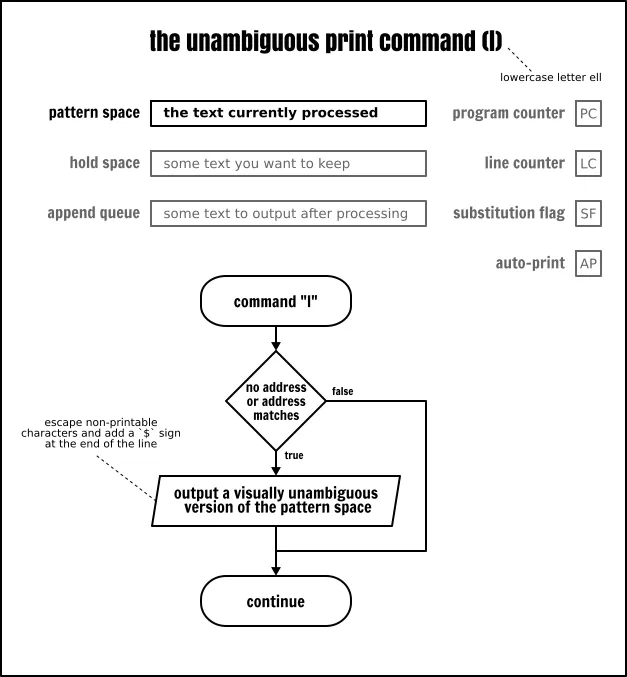
我怀疑这个命令是在非 8 位规则化信道 上交换数据的。就我本人而言,除了调试用途以外,也从未使用过它。
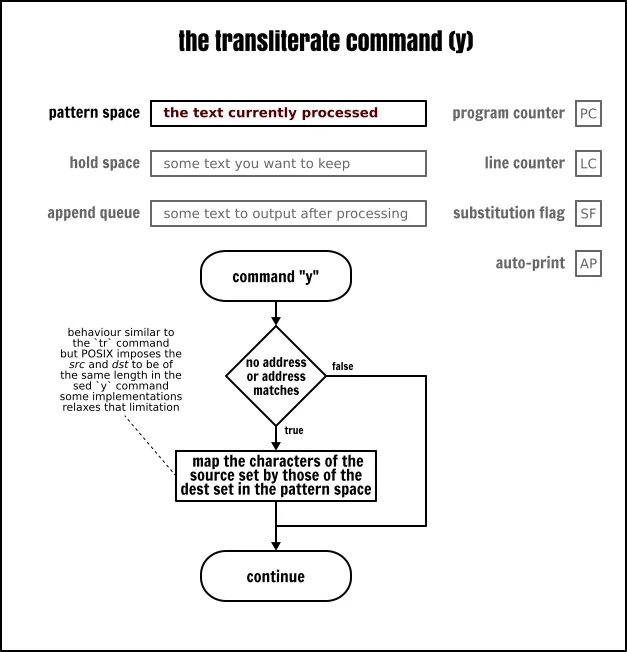
移译命令
移译 (y)命令允许从一个源集到一个目标集映射模式空间的字符。它非常类似于 tr 命令,但是限制更多。
# The `y` c0mm4nd 1s for h4x0rz only
sed < inputfile -e '
s/:.*//
y/abcegio/48<3610/
'虽然移译命令语法与替换命令的语法有一些相似之处,但它在替换字符串之后不接受任何选项。这个移译总是全局的。
请注意,移译命令要求源集和目标集之间要一一对应地转换。这意味着下面的 Sed 程序可能所做的事情并不是你乍一看所想的那样:
# 注意:这可能并不如你想的那样工作!
sed < inputfile -e '
s/:.*//
y/[a-z]/[A-Z]/
'写在最后的话
# 它要做什么?
# 提示:答案就在不远处...
sed -E '
s/.*W(.*)/1/
h
${ x; p; }
d' < inputfile我们已经学习了所有的 Sed 命令,真不敢相信我们已经做到了!如果你也读到这里了,应该恭喜你,尤其是如果你花费了一些时间,在你的系统上尝试了所有的不同示例!
正如你所见,Sed 是非常复杂的,不仅因为它的语法比较零乱,也因为许多极端案例或命令行为之间的细微差别。毫无疑问,我们可以将这些归结于历史的原因。尽管它有这么多缺点,但是 Sed 仍然是一个非常强大的工具,甚至到现在,它仍然是 Unix 工具箱中为数不多的大量使用的命令之一。是时候总结一下这篇文章了,没有你们的支持我将无法做到:请节选你对喜欢的或最具创意的 Sed 脚本,并共享给我们。如果我收集到的你们共享出的脚本足够多了,我将会把这些 Sed 脚本结集发布!
via: https://linuxhandbook.com/sed-reference-guide/
作者:Sylvain Leroux 选题:lujun9972 译者:qhwdw 校对:wxy
发表回复