

截断(形容词):缩写、删节、缩减、剪切、剪裁、裁剪、修剪……
数据项被截断的一种情况是将其输入到数据库字段中,该字段的字符限制比数据项的长度要短。例如,字符串:
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA是 60 个字符长。如果你将其输入到具有 50 个字符限制的“位置”字段,则可以获得:
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #末尾带有一个空格截断也可能导致数据错误,比如你打算输入:
Sally Ann Hunter (aka Sally Cleveland)但是你忘记了闭合的括号:
Sally Ann Hunter (aka Sally Cleveland这会让使用数据的用户觉得 Sally 是否有被修剪掉了数据项的其它的别名。
截断的数据项很难检测。在审核数据时,我使用三种不同的方法来查找可能的截断,但我仍然可能会错过一些。
数据项的长度分布。第一种方法是捕获我在各个字段中找到的大多数截断的数据。我将字段传递给 awk 命令,该命令按字段宽度计算数据项,然后我使用 sort 以宽度的逆序打印计数。例如,要检查以 tab 分隔的文件 midges 中的第 33 个字段:
awk -F"t" 'NR>1 {a[length($33)]++}
END {for (i in a) print i FS a[i]}' midges | sort -nr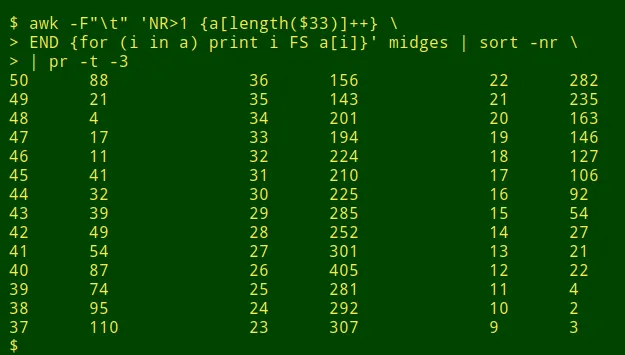
最长的条目恰好有 50 个字符,这是可疑的,并且在该宽度处存在数据项的“凸起”,这更加可疑。检查这些 50 个字符的项目会发现截断:
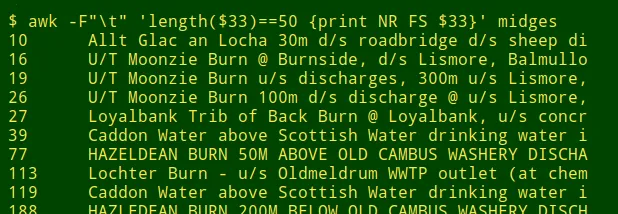
我用这种方式检查的其他数据表有 100、200 和 255 个字符的“凸起”。在每种情况下,这种“凸起”都包含明显的截断。
未匹配的括号。第二种方法查找类似 ...(Sally Cleveland 的数据项。一个很好的起点是数据表中所有标点符号的统计。这里我检查文件 mag2:
grep -o "[[:punct:]]" file | sort | uniqc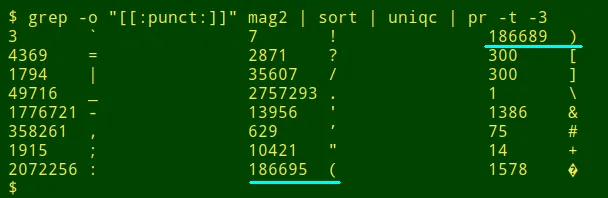
请注意,mag2 中的开括号和闭括号的数量不相等。要查看发生了什么,我使用 unmatched 函数,它接受三个参数并检查数据表中的所有字段。第一个参数是文件名,第二个和第三个是开括号和闭括号,用引号括起来。
unmatched()
{
awk -F"t" -v start="$2" -v end="$3"
'{for (i=1;i<=NF;i++)
if (split($i,a,start) != split($i,b,end))
print "line "NR", field "i":n"$i}' "$1"
}如果在字段中找到开括号和闭括号之间不匹配,则 unmatched 会报告行号和字段号。这依赖于 awk 的 split 函数,它返回由分隔符分隔的元素数(包括空格)。这个数字总是比分隔符的数量多一个:
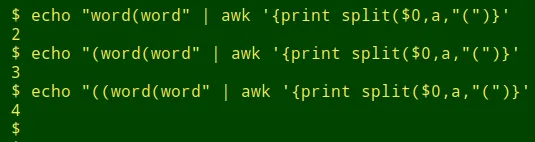
这里 ummatched 检查 mag2 中的圆括号并找到一些可能的截断:
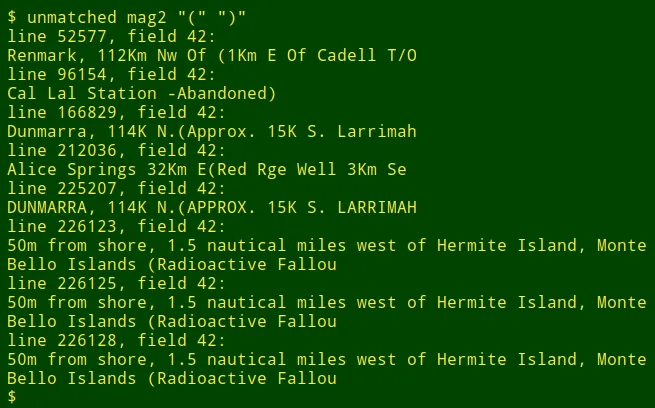
我使用 unmatched 来找到不匹配的圆括号 ()、方括号 []、花括号 {} 和尖括号 <>,但该函数可用于任何配对的标点字符。
意外的结尾。第三种方法查找以尾随空格或非终止标点符号结尾的数据项,如逗号或连字符。这可以在单个字段上用 cut 用管道输入到 grep 完成,或者用 awk 一步完成。在这里,我正在检查以制表符分隔的表 herp5 的字段 47,并提取可疑数据项及其行号:
cut -f47 herp5 | grep -n "[ ,;:-]$"
或
awk -F"t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5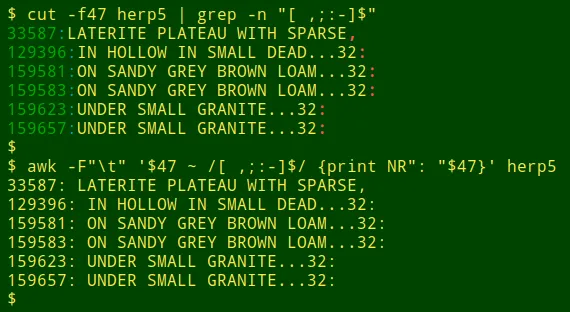
用于制表符分隔文件的 awk 命令的全字段版本是:
awk -F"t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/)
print "line "NR", field "i":n"$i}' file谨慎的想法。在我对字段进行的验证测试期间也会出现截断。例如,我可能会在“年”的字段中检查合理的 4 位数条目,并且有个 198 可能是 198n?还是 1898 年?带有丢失字符的截断数据项是个谜。 作为数据审计员,我只能报告(可能的)字符损失,并建议数据编制者或管理者恢复(可能)丢失的字符。
via: https://www.polydesmida.info/BASHing/2018-07-04.html
作者:polydesmida 选题:lujun9972 译者:wxy 校对:wxy
发表回复