

编者按:本文来自华辰连科技术团队,分享了他们在将浮点运算放到内核态时的探索。
最近我们有一个需求,需要把用户态的浮点数运算全部放到内核态运行,以提高运行速度,移植的过程中发现问题没有这么简单,然后我们抽丝剥茧,揭开 Linux 对浮点处理的原理。
此文章的代码基于 x86 64 位 CPU,Linux 4.14 内核。
一、 Linux 内核添加浮点运算出现的问题
我们以一个简单的浮点运算例子来说明:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/debugfs.h>
#include <asm/fpu/api.h>
#include <linux/delay.h>
static noinline double float_divide(double float1, double float2)
{
return float1 / float2;
}
static int __init test_float_init(void)
{
double result, float1 = 4.9, float2 = 0.49;
result = float_divide(float1, float2);
printk("result = %dn", (int)result);
return 0;
}
static void __exit test_float_exit(void)
{
;
}
module_init(test_float_init);
module_exit(test_float_exit);
MODULE_LICENSE("GPL");test_float.c
obj-m := test_float.o
KDIR := /lib/modules/$(shell uname -r)/build
all:
make -C $(KDIR) M=$(PWD) modulesMakefile
这个内核模块就是计算了两个浮点数除的结果,然后将结果打印出来 。但是我们执行 make 编译的时候发现报错:
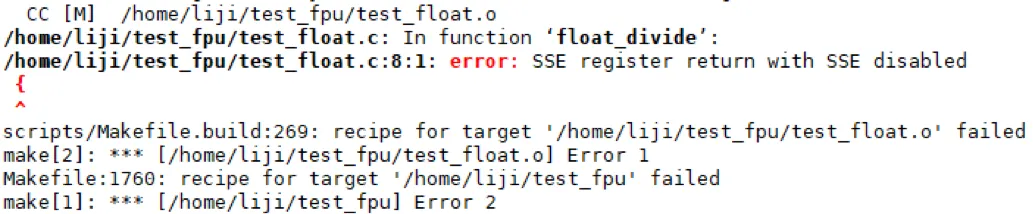
提示 SSE 寄存器返回的报错信息为 “SSE disabled”。我们执行 make V=1 查看关键的编译信息:
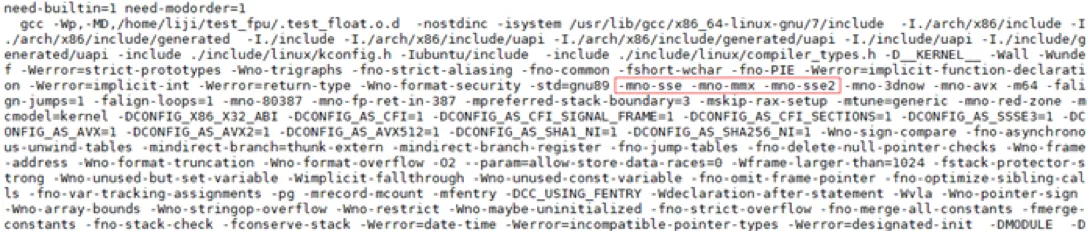
我们发现在 gcc 的参数中有 -mno-sse -mno-mmx -mno-sse2 选项,原来 gcc 默认的编译选项禁用了 sse、mmx、sse2 等浮点运算指令。
二、通过添加 gcc 编译参数和 kernel_fpu_begin/kernel_fpu_end 来解决问题
为了让内核支持浮点运算,我们在 Makefile 中添加支持 sse 等选项,源码中添加 kernel_fpu_begin/kernel_fpu_end 函数,修改后的源码如下所示:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/debugfs.h>
#include <asm/fpu/api.h>
#include <linux/delay.h>
static noinline double float_divide(double float1, double float2)
{
return float1 / float2;
}
static int __init test_float_init(void)
{
double result, float1 = 4.9, float2 = 0.49;
kernel_fpu_begin();
result = float_divide(float1, float2);
kernel_fpu_end();
printk("result = %dn", (int)result);
return 0;
}
static void __exit test_float_exit(void)
{
;
}
module_init(test_float_init);
module_exit(test_float_exit);
MODULE_LICENSE("GPL");test_float.c
obj-m := test_float.o
KDIR := /lib/modules/$(shell uname -r)/build
FPU_CFLAGS += -mhard-float
FPU_CFLAGS += -msse -msse2
CFLAGS_test_float.o += $(FPU_CFLAGS)
all:
make -C $(KDIR) M=$(PWD) modulesMakefile
此时执行 make,发现编译正确通过了:

然后 insmod test_float.ko,观察 dmesg 的输出:

从上面的例子,结合内核源码中 arch/x86/Makefile 中的 KBUILD_CFLAGS,可以看到编译内核及内核模块时,gcc 选项继承 Linux 中的规则,指定了 -mno-sse -mno-mmx -mno-sse2,也就是禁用了 FPU 。所以,要想内核模组支持浮点运算,编译选项需要显式的指定 -msse -msse2。
三、 Linux 内核态对浮点运算处理方式的分析
从上面可以看到,我们为了实现一个内核模块的浮点运算,添加了编译参数 -mhard-float和-msse -msse2,对于编译参数来说,-mhard-float 是告诉编译器直接生成浮点运算的指令,而 -msse -msse2 则是告诉编译器可以使用 sse/sse2 指令集来编译代码。
kernel_fpu_begin 和 kernel_fpu_end 也是必须的,因为 Linux 内核为了提高系统的运行速率,在任务上下文切换时,只会保存/恢复普通寄存器的值,并不包括 FPU 浮点寄存器的值,而调用 kernel_fpu_begin 主要作用是关掉系统抢占,浮点计算结束后调用 kernel_fpu_end 开启系统抢占,这使得代码不会被中断,从而安全的进行浮点运算,并且要求这之间的代码不能有休眠或调度操作,另外不得有嵌套的情况出现(将会覆盖原始保存的状态,然后执行 kernel_fpu_end() 最终将恢复错误的 FPU 状态)。
void kernel_fpu_begin(void)
{
preempt_disable();
__kernel_fpu_begin();
}四、三角函数在 Linux 内核态的实现
由于内核态不支持浮点运算,所以像三角函数之类浮点运算都没有实现,如果需要,可以将用户态 glibc 中相关的三角函数的实现移植到内核态。
五、 Linux 用户态对浮点运算处理方式的分析
为什么用户态浮点运算就不需要指定编译选项以及显式调用 kernel_fpu_begin 和 kernel_fpu_end 函数呢?我们在用户态下写一个简单的带浮点运算的例子:
#include <stdio.h>
int main(int argc, char **argv)
{
int result, float1=4.9, float2=0.49;
result = float1 / float2;
printf("result = %dn", result);
return 0;
}user_float.c
我们分别使用下面四条编译指令查看编译出来的汇编:
gcc -S user_float.cgcc -S user_float.c -msoft-floatgcc -S user_float.c -mhard-floatgcc -S user_float.c -msoft-float -mno-sse -mno-mmx -mno-sse2
前三条命令编译成功。依次查看编译生成的汇编代码,发现生成的汇编代码是完全一样的,都是用到了 sse 指令中的 mmx 寄存器,也就是使用到了 FPU。
第四条命令编译失败 ,提示 error: SSE register return with SSE disabled。从上面的现象中我们可以得出结论,系统默认使用 gcc 编译用户态程序时,gcc 默认使用 FPU,也就是使用硬浮点来编译。
经过查阅各种文档和分析代码,x86 CPU 提供如下特性:CPU 提供的 TS 寄存器的第三个位是 任务已切换标志 ,CPU 在每次任务切换时会设置这个位。而且 TS 的这个位被设置时,当进程使用 FPU 指令时 CPU 会产生一个 DNA(Device Not Availabel)异常。Linux 使用此特性,当用户态应用程序进行浮点运算时(SSE 等指令),触发 DNA 异常,同时使用 FPU 专用寄存器和指令来执行浮点数功能,此时 TS_USEDFPU 标志为 1,表示用户态进程使用了 FPU。
void fpu__restore(struct fpu *fpu)
{
fpu__initialize(fpu);
/* Avoid __kernel_fpu_begin() right after fpregs_activate() */
kernel_fpu_disable();
trace_x86_fpu_before_restore(fpu);
fpregs_activate(fpu);
copy_kernel_to_fpregs(&fpu->state);
trace_x86_fpu_after_restore(fpu);
kernel_fpu_enable();
}
EXPORT_SYMBOL_GPL(fpu__restore);假设用户态进程 A 使用到了 FPU 执行浮点运算,此时用户态进程 B 被调度执行,那么当进程 A 被调度出去的时候,内核设置 TS 并调用 fpu__restore 将 FPU 的内容保存。当进程 A 恢复浮点运算执行时,触发 DNA 异常,相应的异常处理程序会恢复 FPU 之前保存的状态。
假设用户态进程 A 使用到了 FPU 执行浮点运算(TS_USEDFPU 标志为 1),此时内核态进程 C 调度并使用 FPU,由于内核只会保存普通的寄存器的值,并不包括 FP 等寄存器的值,所以内核会主动调用 kernel_fpu_begin 函数保存寄存器内容,使用完之后调用 kernel_fpu_end。当用户态进程 A 恢复浮点运算执行时,触发 DNA 异常,相应的异常处理程序会恢复 FPU 寄存器的内容。
六、 结论
- Linux 中当任务切换时,缺省不保存浮点器寄存器。
- 如果需要内核态支持浮点运算,需要增加支持浮点的编译选项和使用
kernel_fpu_begin和kernel_fpu_end函数手动处理上下文。 - 用户态缺省支持浮点运算,但是需要内核来辅助。
发表回复