

我们都知道如何从键盘输入文字,不是吗?
那么,请允许我挑战你在你最爱的文本编辑器中输入这段文字:

这段文字难以被输入因为它包含着:
- 键盘上没有的印刷符号,
- 平假名日文字符,
- 为符合平文式罗马字标准,日本首都的名字中的两个字母 “o” 头顶带有长音符号,
- 以及最后,用西里尔字母拼写的名字德米特里。
毫无疑问,想要在早期的电脑中输入这样的句子是不可能的。这是因为早期电脑所使用的字符集有限,无法兼容多种书写系统。而如今类似的限制已不复存在,马上我们就能在文中看到。
电脑是如何储存文字的?
计算机将字符作为数字储存。它们再通过表格将这些数字与含有意义的字形一一对应。
在很长一段时间里,计算机将每个字符作为 0 到 255 之间的数字储存(这正好是一个字节的长度)。但这用来代表人类书写所用到的全部字符是远远不够的。而解决这个问题的诀窍在于,取决于你住在地球上的哪一块区域,系统会分别使用不同的对照表。
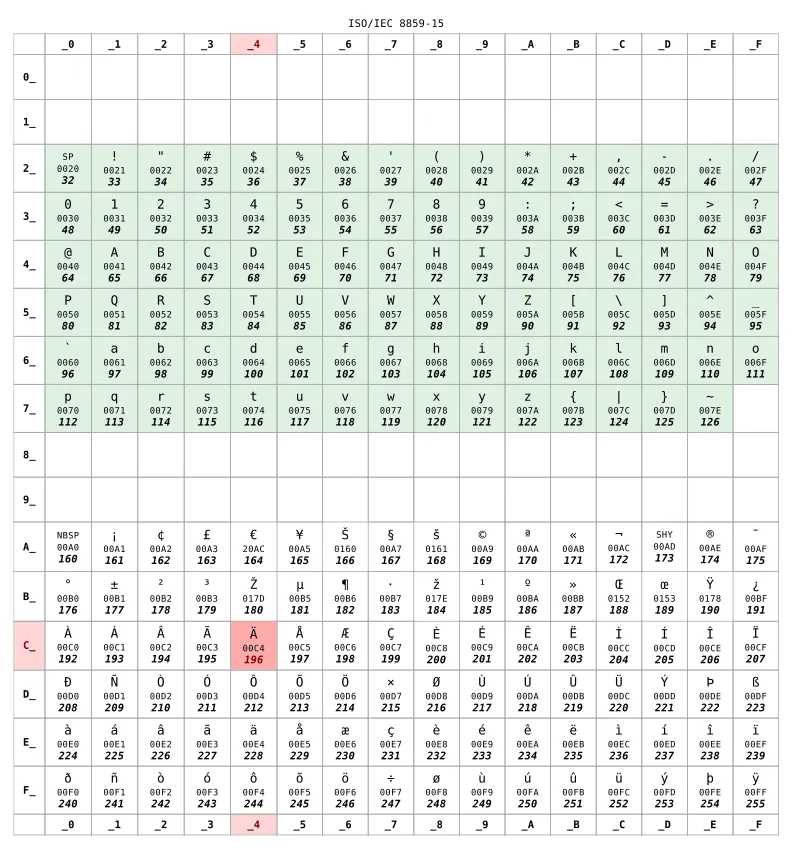
这里有一张在法国常被广泛使用的对照表 ISO 8859-15:
如果你住在俄罗斯,你的电脑大概会使用 KOI8-R 或是 Windows-1251 来进行编码。现在让我们假设我们在使用后者:
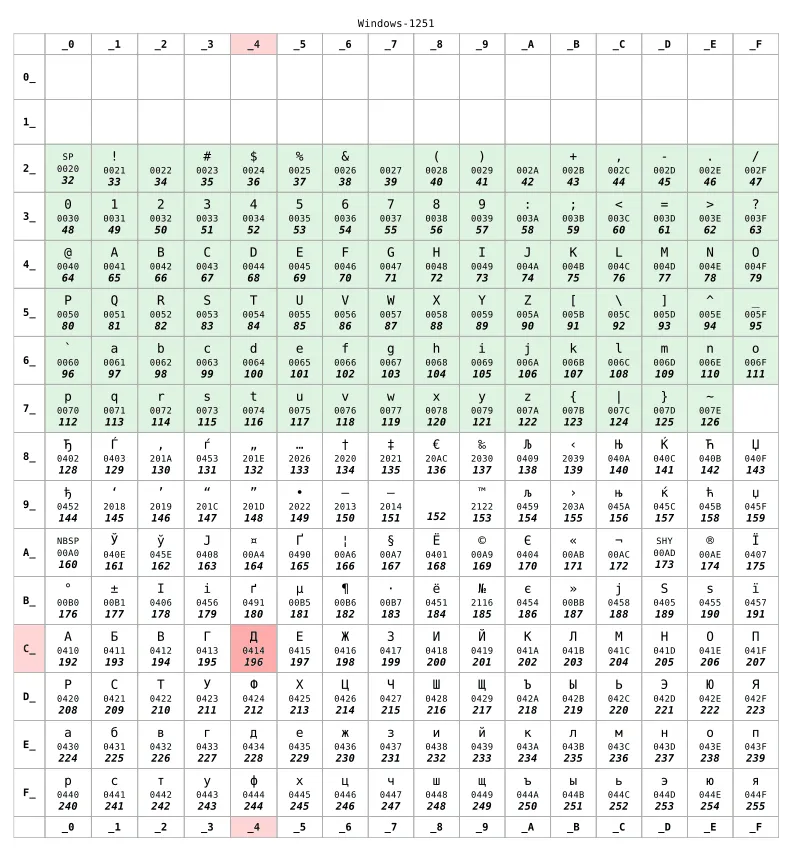
对于 128 之前的数字,两张表格是一样的。这个范围与 US-ASCII 相对应,这是不同字符表格之间的最低兼容性。而对于 128 之后的数字,这两张表格则完全不同了。
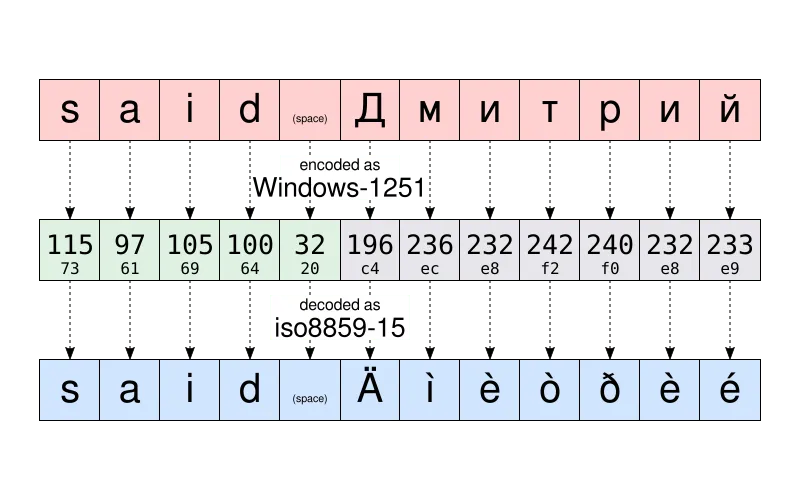
比如,依据 Windows-1251,字符串 “said Дмитрий” 会被储存为:
115 97 105 100 32 196 236 232 242 240 232 233
按照计算机科学的常规方法,这十二个数字可被写成更加紧凑的十六进制:
73 61 69 64 20 c4 ec e8 f2 f0 e8 e9
如果德米特里发给我这份文件,我在打开后可能会看到:
said Äìèòðèé
这份文件 看起来 被损坏了,实则不然。这些储存在文件里的数据,即数字,并没有发生改变。被显示出的字符与 另一张表格 中的数据相对应,而非文字最初被写出来时所用的编码表。
让我们来举一个例子,就以字符 “Д” 为例。按照 Windows-1251,“Д” 的数字编码为 196(c4)。储存在文件里的只有数字 196。而正是这同样的数字在 ISO8859-15 中与 “Ä” 相对应。这就是为什么我的电脑错误地认为字形 “Ä” 就是应该被显示的字形。
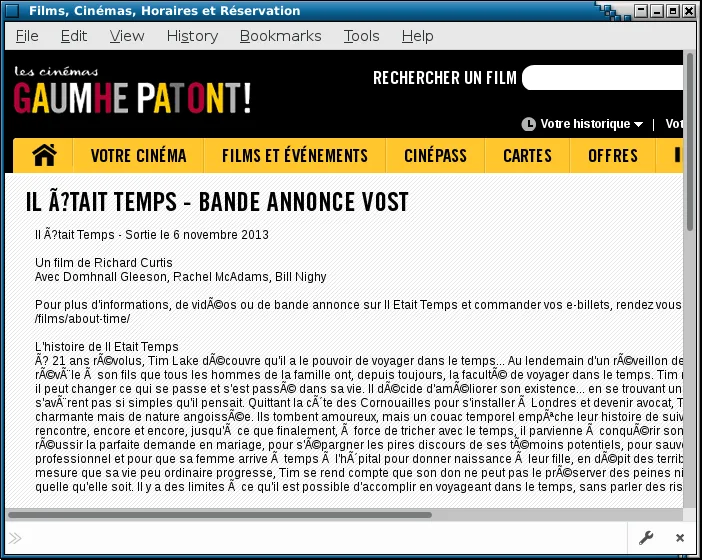
多提一句,你依然可以时不时地看到一些错误配置的网站展示,或由 用户邮箱代理 发出的对收件人电脑所使用的字符编码做出错误假设的邮件。这样的故障有时被称为乱码(LCTT 译注:原文用词为 mojibake, 源自日语 文字化け)。好在这种情况在今天已经越来越少见了。
Unicode 拯救了世界
我解释了不同国家间交换文件时会遇到的编码问题。但事情还能更糟,同一个国家的不同生产商未必会使用相同的编码。如果你在 80 年代用 Mac 和 PC 互传过文件你就懂我是什么意思了。
也不知道是不是巧合,Unicode 项目始于 1987 年,主导者来自 施乐 和…… 苹果 。
这个项目的目标是定义一套通用字符集来允许同一段文字中 同时 出现人类书写会用到的任何文字。最初的 Unicode 项目被限制在 65536 个不同字符(每个字符用 16 位表示,即每个字符两字节)。这个数字已被证实是远远不够的。
于是,在 1996 年 Unicode 被扩展以支持高达 100 万不同的 代码点 。粗略来说,一个“代码点”可被用来识别字符表中的一个条目。Unicode 项目的一个核心工作就是将世界上正在被使用(或曾被使用)的字母、符号、标点符号以及其他文字仓管起来,并给每一项条目分配一个代码点用以准确分辨对应的字符。
这是一个庞大的项目:为了让你有个大致了解,发布于 2017 年的 Unicode 版本 10 定义了超过 136,000 个字符,覆盖了 139 种现代和历史上的语言文字。
随着如此庞大数量的可能性,一个基本的编码会需要每个字符 32 位(即 4 字节)。但对于主要使用 US-ASCII 范围内字符的文字,每个字符 4 字节意味着 4 倍多的储存需求以及 4 倍多的带宽用以传输这些文字。
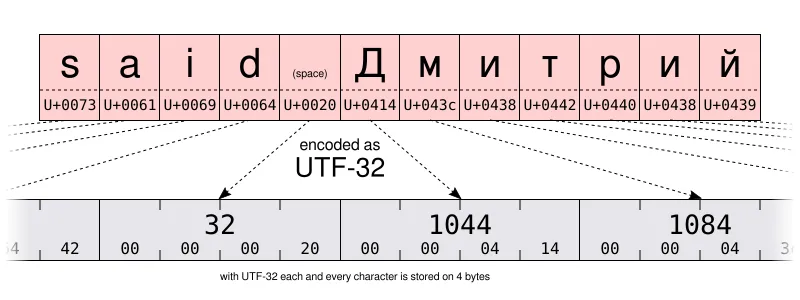
所以除了 UTF-32,Unicode 联盟还定义了更加节约空间的 UTF-16 和 UTF-8 编码,分别使用了 16 位和 8 位。但只有 8 位该如何储存超过 100,000 个不同的值呢?事实是,你不能。但这其中窍门在于用一个代码值(UTF-8 中的 8 位以及 UTF-16 中的 16 位)来储存最常用的一些字符。再用几个代码值储存最不常用的一些字符。所以说 UTF-8 和 UTF-16 是 可变长度 编码。尽管这样也有缺陷,但 UTF-8 是空间与时间效率之间一个不错的折中。更不用提 UTF-8 可以向后兼容大部分 Unicode 之前的 1 字节编码,因为 UTF-8 经过了特别设计,任何有效的 US-ASCII 文件都是有效的 UTF-8 文件。你也可以说,UTF-8 是 US-ASCII 的超集。而在今天已经找不到不用 UTF-8 编码的理由了。当然除非你书写主要用的语言需要多字节编码,或是你不得不与一些残留的老旧系统打交道。
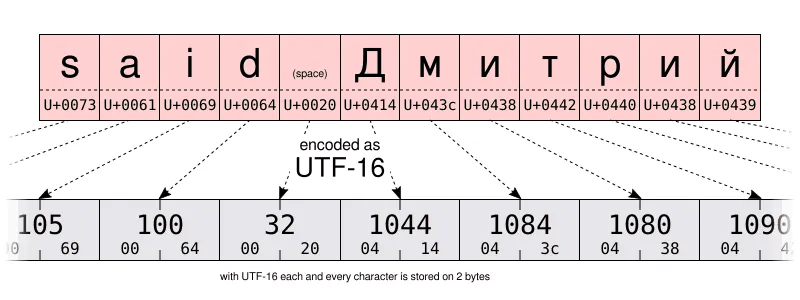
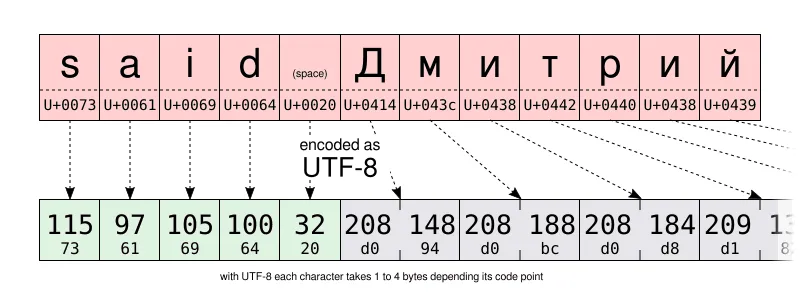
在下面两张图中,你可以亲自比较一下同一字符串的 UTF-16 和 UTF-8 编码。特别注意 UTF-8 使用了一字节来储存拉丁字母表中的字符,但它使用了两字节来存储西里尔字母表中的字符。这是 Windows-1251 西里尔编码储存同样字符所需空间的两倍。
而这些对于打字有什么用呢?
啊……知道一些你的电脑的能力与局限以及其底层机制也不是什么坏事嘛。特别是我们马上就要说到 Unicode 和十六进制。现在……让我们再聊点历史。真的就一点,我保证……
……就说从 80 年代起,电脑键盘曾经有过 Compose 键(有时候也被标为 Multi 键)就在 Shift 键的下边。当按下这个键时,你会进入 “ 组合 ” 模式。一旦在这个模式下,你便可以通过输入助记符来输入你键盘上没有的字符。比如说,在组合模式下,输入 RO 便可生成字符 ®(当作是 O 里面有一个 R 就能很容易记住)。

现在很难在现代键盘上看到 Compose 键了。这大概是因为占据主导地位的 PC 不再用它了。但是在 Linux 上(可能还有其他系统)你可以模拟 Compose 键。这项设置可以通过 GUI 开启,在大多数桌面环境下调用“键盘”控制面板:但具体的步骤取决于你的桌面环境以及版本。如果你成功启用了那项设置,不要犹豫,在评论区分享你在你电脑上所采取的具体步骤。
(LCTT 译注:如果有读者想要尝试,建议将 Compose 键设为大写锁定键,或是别的不常用的键,Ctrl 和 Alt 会被大部分 GUI 程序优先识别为功能键。还有一些我自己试验时遇到过的问题,在开启 Compose 键前要确认大写锁定是关闭的,输入法要切换成英文,组合模式下输入大小写敏感。我试验的系统是 Ubuntu 22.04 LTS。)
至于我自己嘛,我现在先假设你用的就是默认的 Shift+AltGr 组合来模拟 Compose 键。(LCTT 校注:AltGr 在欧洲键盘上是指右侧的 Alt 键,在国际键盘上等价于 Ctrl+Alt 组合键。)
那么,作为一个实际例子,尝试输入 “LEFT-POINTING DOUBLE ANGLE QUOTATION MARK(左双角引号)”(LCTT 译注:Guillemet,是法语和一些欧洲语言中的引号,与中文的书名号不同),你可以输入 Shift+AltGr <<(你在敲助记符时不需要一直按着 Shift+AltGr)。如果你成功输入了这个符号,你自己应该也能猜到要怎么输入 “RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK(右双角引号)” 了。
来看看另一个例子,试试 Shift+AltGr | | |Ctrl+Shift+u`3042 Enter | Alt+12354 | あ |
| Ctrl+Shift+u 3086 Enter | Alt+12422 | ゆ |
| Ctrl+Shift+u 307F Enter | Alt+12415 | み |
死键
最后值得一提的是,想要不(必须)依赖 Compose 键来输入键组合还有一个更简单的方法。
你的键盘上的某些键是专门用来创造字符组合的。这些键叫做 死键 。这是因为当你按下它们一次,看起来什么都没有发生,但它们会悄悄地改变你下一次按键所产生的字符。这个行为的灵感来自于机械打字机:在使用机械打字机时,按下一个死键会印下一个字符,但不会移动字盘。于是下一次按键则会在同一个地方印下另一个字符。视觉效果就是两次按键的组合。
我们在法语里经常用到这个。举例来说,想要输入字母 ë 我必须按下死键 ¨ 然后再按下 e 键。同样地,西班牙人的键盘上有着死键 ~。而在北欧语系下的键盘布局,你可以找到 ° 键。我可以念很久这份清单。
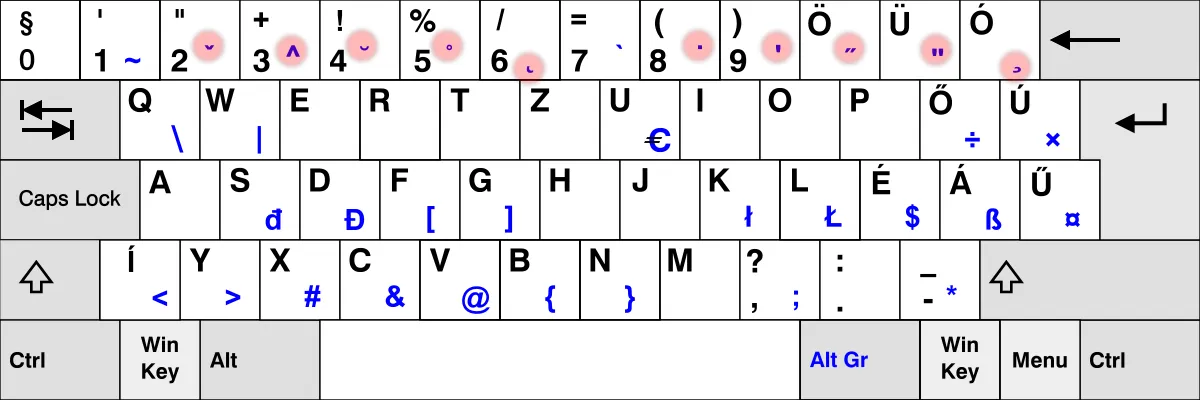
显然,不是所有键盘都有所有死键。实际上,你的键盘上是找不到大部分死键的。比如说,我猜在你们当中只有小部分人——如果真的有的话——有死键 ¯ 来输入 Tōkyō 所需要的长音符号(“平变音符”)。
对于那些你键盘上没有的死键,你需要寻找别的解决方案。好消息是,我们已经用过那些技术了。但这一次我们要用它们来模拟死键,而非“普通”键。
那么,我们的第一个选择是利用 Compose - 来生成长音符号(你键盘上有的连字符减号)。按下时屏幕上什么都不会出现,但当你接着按下 o 键你就能看到 ō。
Gtk 在组合模式下可以生成的一系列死键都能在 这里 找到。
另一个解决方法则是利用 Unicode 字符 “COMBINING MACRON(组合长音符号)”(U+0304),然后字母 o。我把细节都留给你。但如果你好奇的话,你会发现你打出的结果有着微妙的不同,你并没有真地打出 “LATIN SMALL LETTER O WITH MACRON(小写拉丁字母 O 带长音符号)”。我在上一句话的结尾用了大写拼写,这就是一个提示,引导你寻找通过 Unicode 组合字符按更少的键输入 ō 的方法……现在我将这些留给你的聪明才智去解决了。
轮到你来练习了!
所以,你都学会了吗?这些在你的电脑上工作吗?现在轮到你来尝试了:根据上面提出的线索,加上一点练习,现在你可以完成文章开头给出的挑战了。挑战一下吧,然后把成果复制到评论区作为你成功的证明。
赢了也没有奖励,或许来自同伴的惊叹能够满足你!
via: https://itsfoss.com/unicode-linux/
作者:Sylvain Leroux 选题:lkxed 译者:yzuowei 校对:wxy
发表回复