

研究一下这个框架,来建立你自己的开源项目的数据分析。
在数据分析的黄金时代,开源社区也不能免俗。大家都热衷于将一些华丽的数字放到演示幻灯片上,但如果你掌握了正确的分析方法,这些信息可以为你带来更大的价值。
或许你认为作为一名 数据科学家,我会告诉你数据分析和自动化能为你的社区决策提供信息。但实际上,情况恰恰相反。利用数据分析来构建你现有的开源社区知识,吸收其他的知识,并发现潜在的偏见和没有思考过的观点。你或许是实施社区活动的专家,而你那些同事则是代码方面的专家。当你们每个人都在自己的知识背景下将信息可视化时,你们都可以从这些信息中受益。
让我们来面对现实吧。每个人都有一千零一件事情要做,而且总感觉一天的时间永远不够用。如果需要几个小时才能得到你的社区的答案,你就不可能有足够的精力去解决这些事情。但是,花时间创建一个全面发展的可视化项目,可以帮助你时刻掌握你所关心的社区的不同方面,这就将你从精疲力尽中解放了出来。
随着“数据驱动”思维的盛行,围绕开源社区的信息宝库可能是一种祝福,也可能是一种诅咒。下面我将分享一些方法,告诉你如何从数据干草堆中挑出有价值的信息。
你的预期是什么?
当考虑一个指标时,首先要明确你想提供的观点。以下是几个可能涉及的概念:
告知性和影响性的行动: 你的社区是否存在某个领域尚未被理解?你是否已迈出第一步?你是否试图确定特定方向?你是否正在衡量现有倡议的效果?
暴露需要改进的领域和突出优势: 有时你想宣传你的社区,突出它的优势,特别是在试图证明商业影响或为项目宣传时。然而,当涉及到向社区内部传递信息时,你通常需要从一堆指标中精准的找到你们的缺点,以此来帮助你们改进。虽然突出优点并非不可取,但需要在适当的时间和地点。不要把优势指标作为社区内部的拉拉队,告诉每个人都有多棒,而是要与外界分享,以获得认可或推广。
社区和商业影响: 数字和数据是许多企业的语言。但是这可能使得为你的社区进行宣传并真正展示其价值变得异常困难。数据可以成为用他们的语言说话的一种方式,并展示他们想看到的东西,以使你数据背后的潜在含义能够被有效转达。另一个角度是对开源的整体影响。你的社区是如何影响他人和生态系统的?
这些观点并非非此即彼,而是相互关联的。适当的框架将有助于创造一个更深思熟虑的衡量标准。
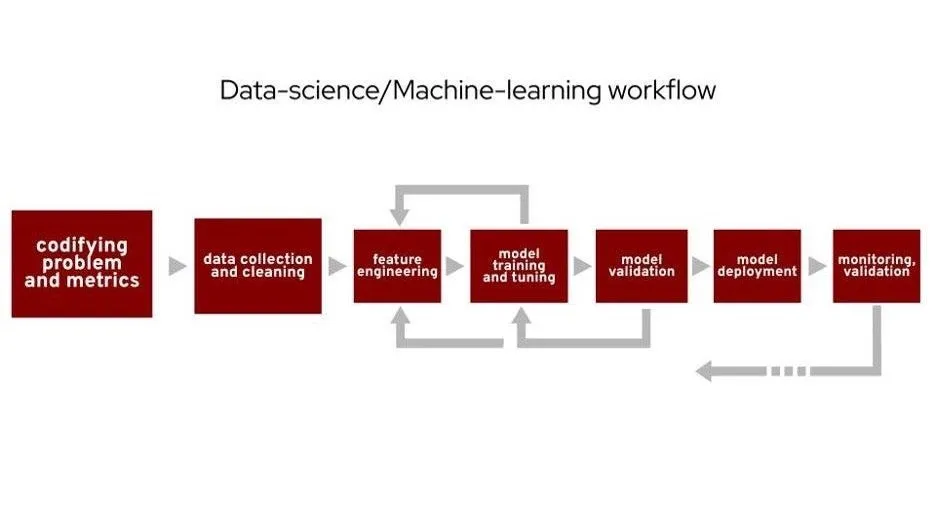
当人们谈论通用的数据科学或机器学习工作时,通常会描述这样的工作流程。我将重点关注第一步,即编写问题和度量标准,并简要提及第二步。从数据科学的角度来看,这个演示可以被视为这个步骤的一个案例研究。这一步有时会被忽视,但你的分析的实际价值始于此。你不能一天醒来就知道要看什么。从理解你想知道什么和你所拥有的数据开始,逐步实现更加深度的数据分析。
3个开源数据分析用例
以下是您在开源数据分析过程中可能遇到的三种不同场景。
场景 1:现有数据分析
假设你开始进行分析,并且已经知道你将要研究的内容对你或你的社区是有用的。那么你该如何提高分析的价值呢?这里的想法是建立在“传统”的开源社区分析基础之上。假设你的数据表明,在项目的整个生命周期内,你共有 120 个贡献者。这是你可以放在幻灯片上的价值,但你不能从中做出决策。从仅有一个数字到获得洞见,逐步采取措施。例如,你可以从相同的数据中将贡献者分为活跃和流失的贡献者(那些已经有一段时间没有做出贡献的贡献者),以获得更深入的了解。
场景 2:社区活动的影响测量
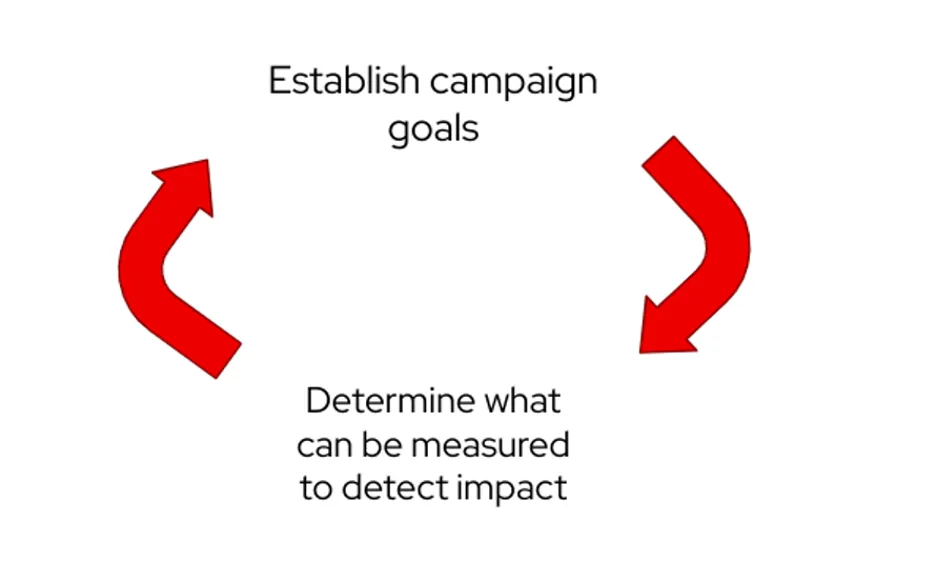
针对聚会、会议或其他任何社区外联活动,你如何看待你的影响力和目标?这两个步骤实际上互相影响。一旦你确定了活动的目标,就要确定可以用什么来检测效果。这些信息有助于设定活动的目标。在活动开始时,很容易陷入模糊的计划而非具体的计划的陷阱中。
场景3:形成新的影响分析区
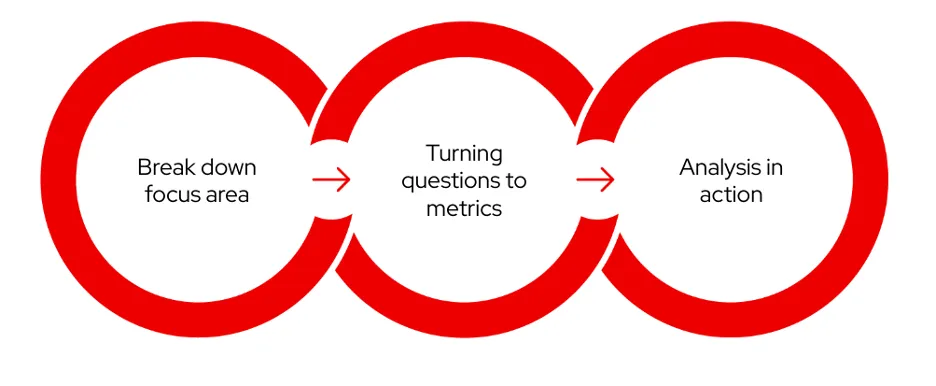
当你从头开始进行数据分析时,就会出现这种情况。前面的例子是这个工作流程的不同部分。这个工作流程是一个不断发展的循环;你可以随时进行改进或扩展。基于这个概念,以下是你应该经历的必要步骤。在本文的后面,将会有三个不同的例子,展示这种方法在现实世界中的应用。
第一步:分解关注区和视角
首先,想象一下魔法 8 球——你可以问任何问题,摇一摇,就能得到答案的玩具。考虑你的分析领域。如果你能立即得到任何答案,那会是什么?
接下来,考虑数据。从你的魔法 8 球问题中,哪些数据源可能与问题或关注领域有关?
在数据背景下,哪些问题可以回答,让你更接近你提出的魔法 8 球问题?需要注意的是,如果你试图将所有的数据汇集在一起,你必须考虑到所做出的假设。
第二步:将问题转化为指标
以下是第一步中每个子问题的处理过程:
- 选择所需的具体数据点。
- 确定可视化以实现目标分析。
- 假设这些信息的影响。
接下来,引入社区提供反馈并触发迭代开发过程。这个协作部分可能就是真正的魔力所在。最好的想法通常是在将一个概念带给某个人时产生的,会激发他们的灵感,这是你或他们无法想象的。
第三步:分析实践
这一步是你开始处理你所创建的指标或可视化的影响。
首先要考虑的是,这个度量标准是否符合当前对社区的了解。
- 如果是:是否有假设得出的结果?
- 如果不是:你需要进一步调查,是否这是一个潜在的数据或计算问题,或者只是先前被误解的社区的一部分。
一旦你确定你的分析足够稳定,可以开始在信息上实施社区倡议。当你正在进行分析以确定下一步最佳步骤时,你应该确定衡量倡议成功的具体方法。
现在,观察这些由你的指标提供信息的社区倡议。确定是否可以用你之前建立的成功衡量指标观察到影响。如果没有,可以考虑以下几点:
- 你是否在衡量正确的事情?
- 倡议战略是否需要调整?
分析区的例子:新贡献者
魔法 8 球问题是什么?
- 如何分析哪些人为持续的贡献者?
我有什么数据可以纳入分析区和魔法 8 球问题?
- 仓库存在哪些贡献者的活动,包括时间戳?
现在你有了这些信息和一个魔法 8 球问题,把分析分成几个子部分执行。这个想法与上述步骤 2 和 3 相关。
子问题 1: “人们是怎么进入这个项目的”
这个问题的目的是先看看新的贡献者在做什么。
数据: GitHub 上的首次贡献随时间推移的数据(议题、PR、评论等)。
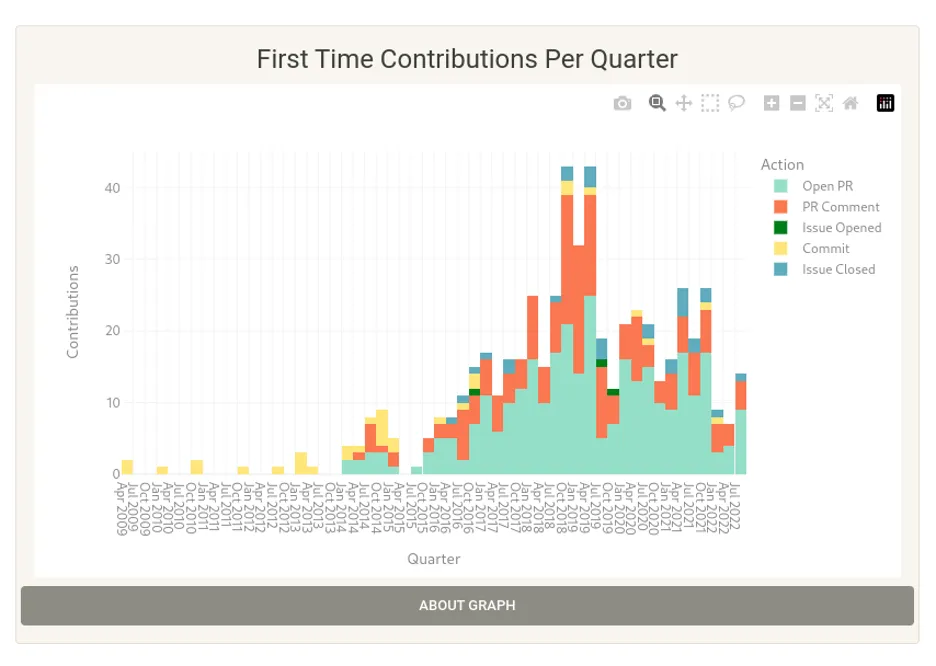
可视化: 按季度划分的首次贡献条形图。
潜在的意义: 在你与其他社区成员交谈后,进一步检查按季度细分的信息,以及贡献者是否为重复贡献者或仅仅是路过。你可以看到人们进来的时候在做什么,以及这是否能告诉你他们是否会留下来。
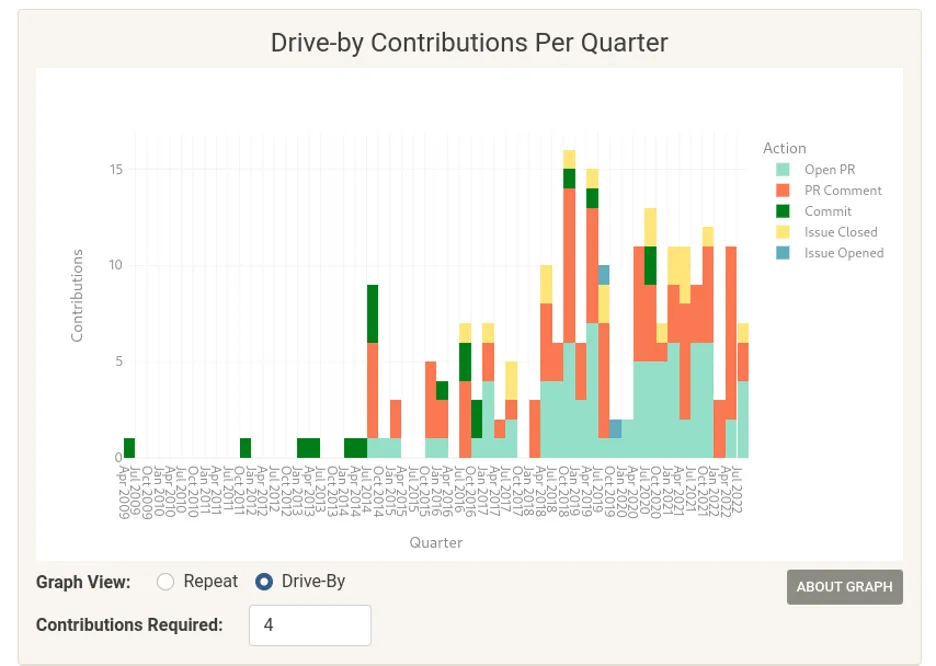
从这些信息中了解到的可以采取的行动。
- 目前的文档是否能够帮助到最常见的新手?你能不能更好地帮助和支持新人朋友,这将有助于他们中更多的人留下来?
- 是否有一个贡献领域在整体上并不常见,但重复贡献者却集中在这个区域?也许 PR 是重复贡献者的一个常见区域,但大多数人却不在这个区域工作。
行动项目:
- 给 “好的第一个问题” 贴上一致的标签,并将这些问题链接到贡献文档中。
- 在这些问题上添加一个 PR 伙伴。
子问题 2: “我们的代码库真的依赖于路过的贡献者吗?”
数据: GitHub 的贡献数据。
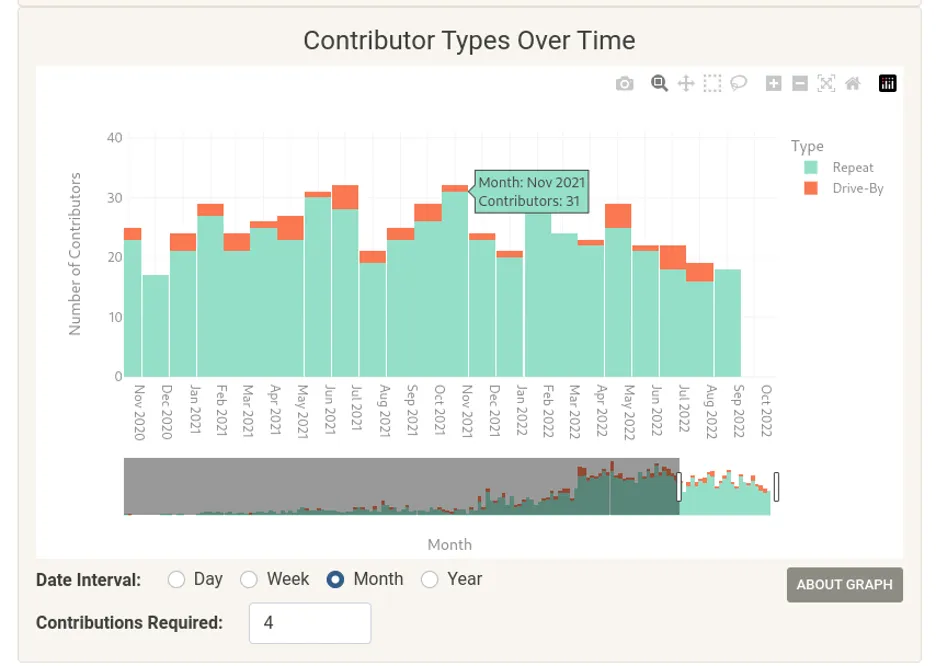
可视化: “贡献总额:按路过和重复贡献者的贡献进行细分。”
根据这一信息可能采取的行动。
- 这个比例是否达到了项目的目标?很多工作都是由路过贡献者完成的吗?这是否是一种未被充分利用的资源,项目是否没有尽到自己的责任来吸引他们?
分析:吸取教训
数字和数据分析并不是“事实”,它们可以支持任何观点。因此,在处理数据时,内部怀疑者应该非常积极,并进行反复迭代,以带来真正的价值。你不希望你的分析只是一个 “yes man”,因此花点时间退一步,评估你所做的假设。
如果一个指标只是指出了调查的方向,那也是一个巨大的胜利。你不可能看清或想到所有的事情,兔子洞可以是一个好事,对话的起点可以把你带到一个新的地方。
有时,你想测量的东西恰恰不在那里,但你也许能得到有价值的细节。不要假设你有所有的拼图碎片来获得你最初问题的准确答案。如果你开始强迫一个答案或解决方案,你会把自己带入一条由假设引领的危险道路。为分析的方向或目标的改变留出空间,可以让你获得比最初的想法更好的洞察力。
数据只是是一种工具,并不是标准答案,它可以汇集原本无法获得的见解和信息。将你想知道的东西分解成可管理的小块,并在此基础上进行分析,这是最重要的部分。
开源数据分析是一个很好的例子,说明你必须对所有的数据科学采取谨慎态度。
- 主题领域的细微差别是最重要的。
- 通过“问什么/答什么”的工作过程经常被忽视。
- 知道“问什么”可能是最难的部分,当你想出一些有洞察力和创新的东西时,这比你选择的任何工具都要重要。
如果你是一个没有数据科学经验的社区成员,正在寻找开始的地方,我希望这些信息能告诉你,你在这个过程中是多么重要和宝贵。你带来了社区的洞察力和观点。如果你是一个数据科学家或实施指标或可视化的人,你必须倾听你周围的声音,即使你也是一个活跃的社区成员。关于数据科学的更多信息列在本文的最后。
总结
把上面的例子作为建立你自己的开源项目的数据分析的框架。对你的结果有很多问题要问,知道这些问题和它们的答案可以把你的项目引向一个令人兴奋和富有成效的方向。
via: https://opensource.com/article/22/12/data-scientists-guide-open-source-community-analysis
作者:Cali Dolfi 选题:lkxed 译者:Chao-zhi 校对:wxy
发表回复