

至少,这是我的估计。推特并不会询问用户的性别,因此我 写了一个程序 ,根据姓名猜测他们的性别。在那些关注我的人当中,性别分布甚至更糟,83% 的是男性。据我所知,其他的还不全都是女性。
修正第一个数字并不是什么神秘的事:我注意寻找更多支持我兴趣的女性专家,并且关注他们。
另一方面,第二个数字,我只能只能轻微影响一点,但是我也打算改进下。我在推特上的关系网应该代表的是软件行业的多元化未来,而不是不公平的现状。
我应该怎么估算呢
我开始估算我关注的人(推特的上的术语是“朋友”)的性别分布,然后发现这格外的难。推特的分析给我展示了如下的结果, 关于关注我的人的性别估算:
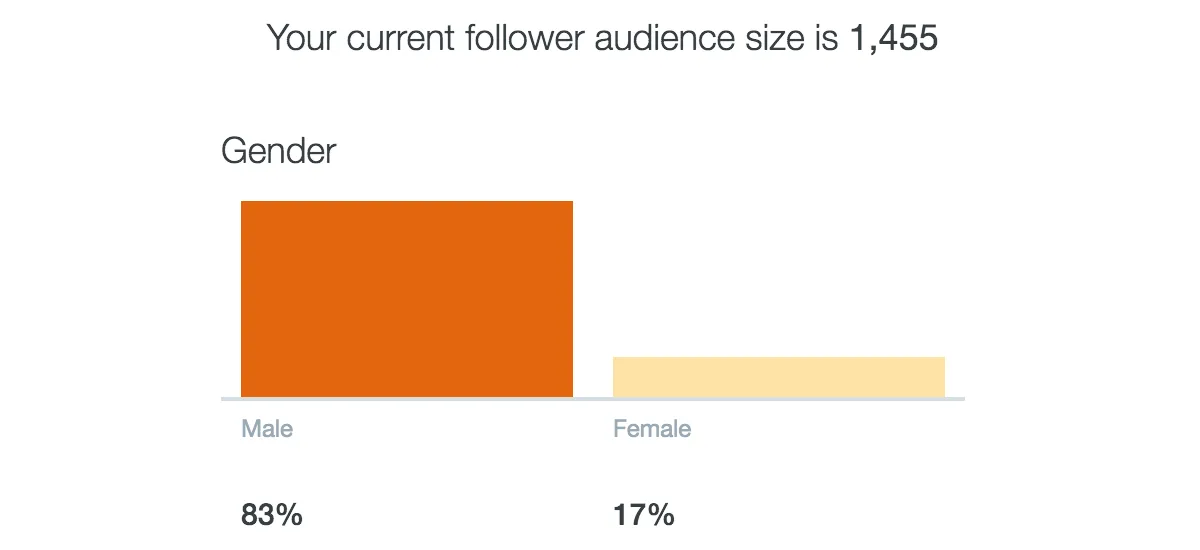
因此,推特的分析将我的关注者分成了三类:男性、女性、未知,并且给我们展示了前面两组的比例。(性别二值化现象在这里并不存在——未知性别的人都集中在组织的推特账号上。)但是我关注的人的性别比例,推特并没有告诉我。 而这就是可以改进的,然后我开始搜索能够帮我估算这个数字的服务,最终发现了 FollowerWonk 。
FollowerWonk 估算我关注的人里面有 71% 都是男性。这个估算准确吗? 为了评估一下,我把 FollowerWonk 和 Twitter 对我关注的人的进行了估算,结果如下:
推特分析
| 男性 | 女性 | |
|---|---|---|
| 我的关注者 | 81% | 19% |
| 我关注的人 | 72% | 28% |
FollowerWonk 的分析显示我的关注者中 81% 的人都是男性,很接近推特分析的数字。这个结果还说得过去。如果FollowerWonk 和 Twitter 在我的关注者的性别比例上是一致的,这就表明 FollowerWonk 对我关注的人的性别估算也应当是合理的。使用 FollowerWonk 我就能养成估算这些数字的爱好,并且做出改进。
然而,使用 FollowerWonk 检测我关注的人的性别分布一个月需要 30 美元,这真是一个昂贵的爱好。我并不需要FollowerWonk 的所有的功能。我能很经济的解决只需要性别分布的问题吗?
因为 FollowerWonk 的估算数字看起来比较合理,我试图做一个自己的 FollowerWonk 。使用 Python 和一些好心的费城人写的 Twitter API 封装类(LCTT 译注:Twitter API 封装类是由 Mike Taylor 等一批费城人在 github 上开源的一个项目),我开始下载我所有关注的人和我所有的关注者的简介。我马上就发现推特的速率限制是很低,因此我随机的采样了一部分用户。
我写了一个初步的程序,在所有我关注的人的简介中搜索一个和性别相关的代词。例如,如果简介中包含了“she”或者“her”这样的字眼,可能这就属于一个女性,如果简介中包含了“they”或者“them”,那么可能这就是性别未知的。但是大多数简介中不会出现这些代词。对于这种简介,和性别关联最紧密的信息就是姓名了。例如:@gvanrossum 的姓名那一栏是“Guido van Rossum”,第一姓名是“Guido”,这表明 @gvanrossum 是一个女的。当找不到代词的时候,我就使用名字来评估性别估算数字。
我的脚本把每个名字的一部分传到性别检测机中去检测性别。性别检测机也有可预见的失败,比如错误的把“Brooklyn Zen Center”当做一个名叫“Brooklyn”的女性,但是它的评估结果与 FollowerWonk 和 Twitter 的相比也是很合理的:
| 非男非女 | 男性 | 女性 | 性别未知的 |
|---|
via: https://emptysqua.re/blog/gender-of-twitter-users-i-follow/
作者:A. Jesse Jiryu Davis 译者:Flowsnow 校对:wxy
发表回复