

介绍
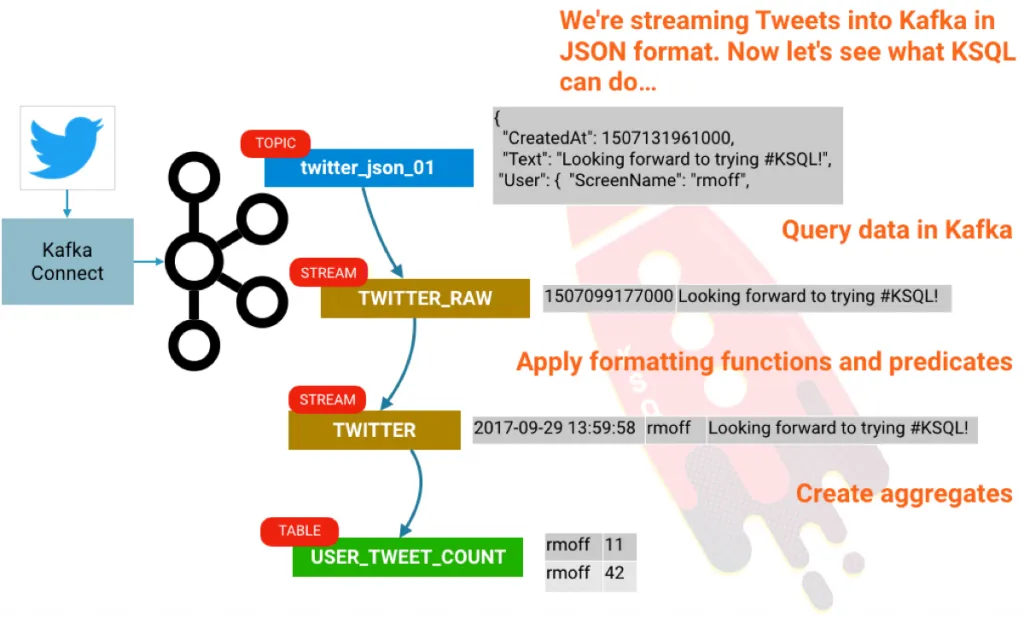
KSQL 是 Apache Kafka 中的开源的流式 SQL 引擎。它可以让你在 Kafka 主题 上,使用一个简单的并且是交互式的 SQL 接口,很容易地做一些复杂的流处理。在这个短文中,我们将看到如何轻松地配置并运行在一个沙箱中去探索它,并使用大家都喜欢的演示数据库源: Twitter。我们将从推文的原始流中获取,通过使用 KSQL 中的条件去过滤它,来构建一个聚合,如统计每个用户每小时的推文数量。
Confluent
首先, 获取一个 Confluent 平台的副本。我使用的是 RPM 包,但是,如果你需要的话,你也可以使用 tar、 zip 等等 。启动 Confluent 系统:
$ confluent start
(如果你感兴趣,这里有一个 Confluent 命令行的快速教程)
我们将使用 Kafka Connect 从 Twitter 上拉取数据。 这个 Twitter 连接器可以在 GitHub 上找到。要安装它,像下面这样操作:
# Clone the git repo
cd /home/rmoff
git clone https://github.com/jcustenborder/kafka-connect-twitter.git
# Compile the code
cd kafka-connect-twitter
mvn clean package
要让 Kafka Connect 去使用我们构建的连接器, 你要去修改配置文件。因为我们使用 Confluent 命令行,真实的配置文件是在 etc/schema-registry/connect-avro-distributed.properties,因此去修改它并增加如下内容:
plugin.path=/home/rmoff/kafka-connect-twitter/target/kafka-connect-twitter-0.2-SNAPSHOT.tar.gz
重启动 Kafka Connect:
confluent stop connect
confluent start connect
一旦你安装好插件,你可以很容易地去配置它。你可以直接使用 Kafka Connect 的 REST API ,或者创建你的配置文件,这就是我要在这里做的。如果你需要全部的方法,请首先访问 Twitter 来获取你的 API 密钥。
{
"name": "twitter_source_json_01",
"config": {
"connector.class": "com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector",
"twitter.oauth.accessToken": "xxxx",
"twitter.oauth.consumerSecret": "xxxxx",
"twitter.oauth.consumerKey": "xxxx",
"twitter.oauth.accessTokenSecret": "xxxxx",
"kafka.delete.topic": "twitter_deletes_json_01",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter.schemas.enable": false,
"kafka.status.topic": "twitter_json_01",
"process.deletes": true,
"filter.keywords": "rickastley,kafka,ksql,rmoff"
}
}
假设你写这些到 /home/rmoff/twitter-source.json,你可以现在运行:
$ confluent load twitter_source -d /home/rmoff/twitter-source.json
然后推文就从大家都喜欢的网络明星 [rick] 滚滚而来……
$ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic twitter_json_01|jq '.Text'
{
"string": "RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB"
}
{
"string": "RT @mariteg10: @rickastley @Carfestevent Wonderful Rick!!nDo not forget Chile!!nWe hope you get back someday!!nHappy weekend for you!!n❤…"
}
KSQL
现在我们从 KSQL 开始 ! 马上去下载并构建它:
cd /home/rmoff
git clone https://github.com/confluentinc/ksql.git
cd /home/rmoff/ksql
mvn clean compile install -DskipTests
构建完成后,让我们来运行它:
./bin/ksql-cli local --bootstrap-server localhost:9092
======================================
= _ __ _____ ____ _ =
= | |/ // ____|/ __ | | =
= | ' /| (___ | | | | | =
= | < ___ | | | | | =
= | . ____) | |__| | |____ =
= |_|______/ __________| =
= =
= Streaming SQL Engine for Kafka =
Copyright 2017 Confluent Inc.
CLI v0.1, Server v0.1 located at http://localhost:9098
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
使用 KSQL, 我们可以让我们的数据保留在 Kafka 主题上并可以查询它。首先,我们需要去告诉 KSQL 主题上的 数据模式 是什么,一个 twitter 消息实际上是一个非常巨大的 JSON 对象, 但是,为了简洁,我们只选出其中几行:
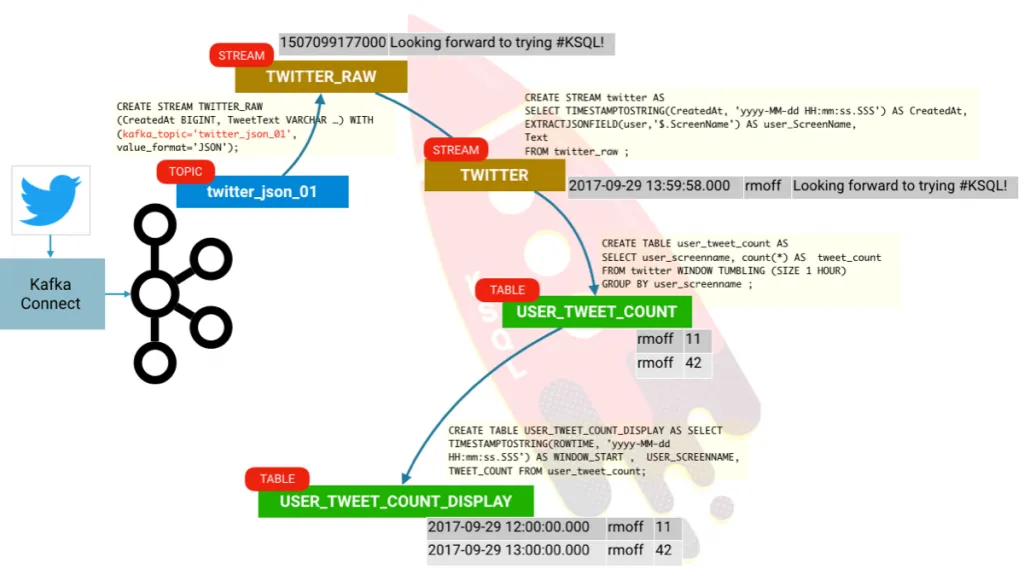
ksql> CREATE STREAM twitter_raw (CreatedAt BIGINT, Id BIGINT, Text VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01', VALUE_FORMAT='JSON');
Message
-
Stream created
ksql>
现在,我们可以操作和检查更多的最近的数据,使用一般的 SQL 查询:
ksql> SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,
EXTRACTJSONFIELD(user,'$.ScreenName') as ScreenName,Text
FROM twitter_raw
WHERE LCASE(hashtagentities) LIKE '%oow%' OR
LCASE(hashtagentities) LIKE '%ksql%';
2017-09-29 13:59:58.000 | rmoff | Looking forward to talking all about @apachekafka & @confluentinc’s #KSQL at #OOW17 on Sunday 13:45 https://t.co/XbM4eIuzeG
注意这里没有 LIMIT 从句,因此,你将在屏幕上看到 “continuous query” 的结果。不像关系型数据表中返回一个确定数量结果的查询,一个持续查询会运行在无限的流式数据上, 因此,它总是可能返回更多的记录。点击 Ctrl-C 去中断然后返回到 KSQL 提示符。在以上的查询中我们做了一些事情:
- TIMESTAMPTOSTRING 将时间戳从 epoch 格式转换到人类可读格式。(LCTT 译注: epoch 指的是一个特定的时间 1970-01-01 00:00:00 UTC)
- EXTRACTJSONFIELD 来展示数据源中嵌套的用户域中的一个字段,它看起来像:
{
"CreatedAt": 1506570308000,
"Text": "RT @gwenshap: This is the best thing since partitioned bread :) https://t.co/1wbv3KwRM6",
[...]
"User": {
"Id": 82564066,
"Name": "Robin Moffatt uD83CuDF7BuD83CuDFC3uD83EuDD53",
"ScreenName": "rmoff",
[...]
- 应用断言去展示内容,对 #(hashtag)使用模式匹配, 使用 LCASE 去强制小写字母。(LCTT 译注:hashtag 是twitter 中用来标注线索主题的标签)
关于支持的函数列表,请查看 KSQL 文档。
我们可以创建一个从这个数据中得到的流:
ksql> CREATE STREAM twitter AS
SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,
EXTRACTJSONFIELD(user,'$.Name') AS user_Name,
EXTRACTJSONFIELD(user,'$.ScreenName') AS user_ScreenName,
EXTRACTJSONFIELD(user,'$.Location') AS user_Location,
EXTRACTJSONFIELD(user,'$.Description') AS user_Description,
Text,hashtagentities,lang
FROM twitter_raw ;
Message
Table created and running
看表中的列,这里除了我们要求的外,还有两个隐含列:
ksql> DESCRIBE user_tweet_count;
Field | Type
Table created and running
现在它更易于查询和查看我们感兴趣的数据:
ksql> SELECT WINDOW_START , USER_SCREENNAME, TWEET_COUNT
FROM USER_TWEET_COUNT_DISPLAY WHERE TWEET_COUNT> 20;
2017-09-29 12:00:00.000 | VikasAatOracle | 22
2017-09-28 14:00:00.000 | Throne_ie | 50
2017-09-28 14:00:00.000 | pikipiki_net | 22
2017-09-29 09:00:00.000 | johanlouwers | 22
2017-09-28 09:00:00.000 | yvrk1973 | 24
2017-09-28 13:00:00.000 | cmosoares | 22
2017-09-29 11:00:00.000 | ypoirier | 24
2017-09-28 14:00:00.000 | pikisec | 22
2017-09-29 07:00:00.000 | Throne_ie | 22
2017-09-29 09:00:00.000 | ChrisVoyance | 24
2017-09-28 11:00:00.000 | ChrisVoyance | 28
结论
所以我们有了它! 我们可以从 Kafka 中取得数据, 并且很容易使用 KSQL 去探索它。 而不仅是去浏览和转换数据,我们可以很容易地使用 KSQL 从流和表中建立流处理。
如果你对 KSQL 能够做什么感兴趣,去查看:
- KSQL 公告
- 我们最近的 KSQL 在线研讨会 和 Kafka 峰会讲演
- clickstream 演示,它是 KSQL 的 GitHub 仓库 的一部分
- 我最近做的演讲 展示了 KSQL 如何去支持基于流的 ETL 平台
记住,KSQL 现在正处于开发者预览阶段。 欢迎在 KSQL 的 GitHub 仓库上提出任何问题, 或者去我们的 community Slack group 的 #KSQL 频道。
via: https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka
作者:Robin Moffatt 译者:qhwdw 校对:wxy
发表回复