
使用 伯克利包过滤器 (BPF) 编译器集合 (BCC)工具深度探查你的 Linux 代码。

在 Linux 中出现的一种新技术能够为系统管理员和开发者提供大量用于性能分析和故障排除的新工具和仪表盘。它被称为 增强的伯克利数据包过滤器 (eBPF,或 BPF),虽然这些改进并不是由伯克利开发的,而且它们不仅仅是处理数据包,更多的是过滤。我将讨论在 Fedora 和 Red Hat Linux 发行版中使用 BPF 的一种方法,并在 Fedora 26 上演示。
BPF 可以在内核中运行由用户定义的沙盒程序,可以立即添加新的自定义功能。这就像按需给 Linux 系统添加超能力一般。 你可以使用它的例子包括如下:
- 高级性能跟踪工具:对文件系统操作、TCP 事件、用户级事件等的可编程的低开销检测。
- 网络性能: 尽早丢弃数据包以提高对 DDoS 的恢复能力,或者在内核中重定向数据包以提高性能。
- 安全监控: 7×24 小时的自定义检测和记录内核空间与用户空间内的可疑事件。
在可能的情况下,BPF 程序必须通过一个内核验证机制来保证它们的安全运行,这比写自定义的内核模块更安全。我在此假设大多数人并不编写自己的 BPF 程序,而是使用别人写好的。在 GitHub 上的 BPF Compiler Collection (bcc) 项目中,我已发布许多开源代码。bcc 为 BPF 开发提供了不同的前端支持,包括 Python 和 Lua,并且是目前最活跃的 BPF 工具项目。
7 个有用的 bcc/BPF 新工具
为了了解 bcc/BPF 工具和它们的检测内容,我创建了下面的图表并添加到 bcc 项目中。
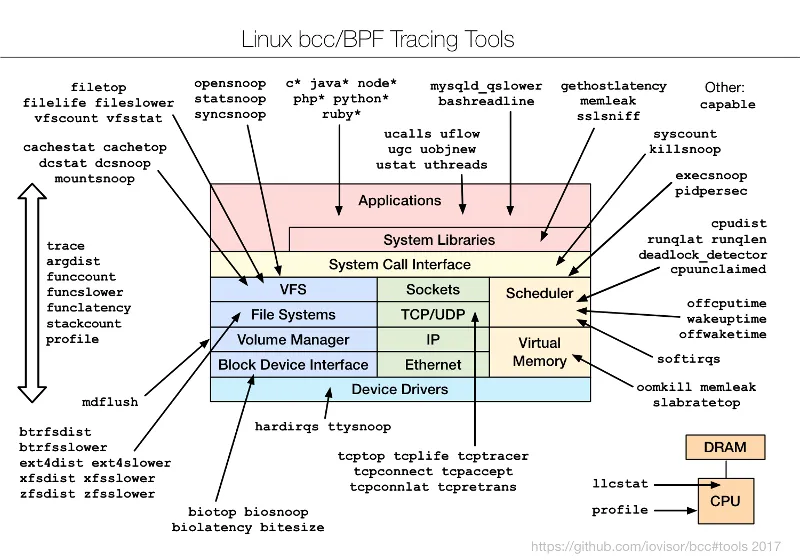
这些是命令行界面工具,你可以通过 SSH 使用它们。目前大多数分析,包括我的老板,都是用 GUI 和仪表盘进行的。SSH 是最后的手段。但这些命令行工具仍然是预览 BPF 能力的好方法,即使你最终打算通过一个可用的 GUI 使用它。我已着手向一个开源 GUI 添加 BPF 功能,但那是另一篇文章的主题。现在我想向你分享今天就可以使用的 CLI 工具。
1、 execsnoop
从哪儿开始呢?如何查看新的进程。那些会消耗系统资源,但很短暂的进程,它们甚至不会出现在 top(1) 命令或其它工具中的显示之中。这些新进程可以使用 execsnoop 进行检测(或使用行业术语说,可以 被追踪 )。 在追踪时,我将在另一个窗口中通过 SSH 登录:
# /usr/share/bcc/tools/execsnoop
PCOMM PID PPID RET ARGS
sshd 12234 727 0 /usr/sbin/sshd -D -R
unix_chkpwd 12236 12234 0 /usr/sbin/unix_chkpwd root nonull
unix_chkpwd 12237 12234 0 /usr/sbin/unix_chkpwd root chkexpiry
bash 12239 12238 0 /bin/bash
id 12241 12240 0 /usr/bin/id -un
hostname 12243 12242 0 /usr/bin/hostname
pkg-config 12245 12244 0 /usr/bin/pkg-config --variable=completionsdir bash-completion
grepconf.sh 12246 12239 0 /usr/libexec/grepconf.sh -c
grep 12247 12246 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
tty 12249 12248 0 /usr/bin/tty -s
tput 12250 12248 0 /usr/bin/tput colors
dircolors 12252 12251 0 /usr/bin/dircolors --sh /etc/DIR_COLORS
grep 12253 12239 0 /usr/bin/grep -qi ^COLOR.*none /etc/DIR_COLORS
grepconf.sh 12254 12239 0 /usr/libexec/grepconf.sh -c
grep 12255 12254 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
grepconf.sh 12256 12239 0 /usr/libexec/grepconf.sh -c
grep 12257 12256 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS
哇哦。 那是什么? 什么是 grepconf.sh? 什么是 /etc/GREP_COLORS? 是 grep 在读取它自己的配置文件……由 grep 运行的? 这究竟是怎么工作的?
欢迎来到有趣的系统追踪世界。 你可以学到很多关于系统是如何工作的(或者根本不工作,在有些情况下),并且发现一些简单的优化方法。 execsnoop 通过跟踪 exec() 系统调用来工作,exec() 通常用于在新进程中加载不同的程序代码。
2、 opensnoop
接着上面继续,所以,grepconf.sh 可能是一个 shell 脚本,对吧? 我将运行 file(1) 来检查它,并使用opensnoop bcc 工具来查看打开的文件:
# /usr/share/bcc/tools/opensnoop
PID COMM FD ERR PATH
12420 file 3 0 /etc/ld.so.cache
12420 file 3 0 /lib64/libmagic.so.1
12420 file 3 0 /lib64/libz.so.1
12420 file 3 0 /lib64/libc.so.6
12420 file 3 0 /usr/lib/locale/locale-archive
12420 file -1 2 /etc/magic.mgc
12420 file 3 0 /etc/magic
12420 file 3 0 /usr/share/misc/magic.mgc
12420 file 3 0 /usr/lib64/gconv/gconv-modules.cache
12420 file 3 0 /usr/libexec/grepconf.sh
1 systemd 16 0 /proc/565/cgroup
1 systemd 16 0 /proc/536/cgroup
像 execsnoop 和 opensnoop 这样的工具会将每个事件打印一行。上图显示 file(1) 命令当前打开(或尝试打开)的文件:返回的文件描述符(“FD” 列)对于 /etc/magic.mgc 是 -1,而 “ERR” 列指示它是“文件未找到”。我不知道该文件,也不知道 file(1) 正在读取的 /usr/share/misc/magic.mgc 文件是什么。我不应该感到惊讶,但是 file(1) 在识别文件类型时没有问题:
# file /usr/share/misc/magic.mgc /etc/magic
/usr/share/misc/magic.mgc: magic binary file for file(1) cmd (version 14) (little endian)
/etc/magic: magic text file for file(1) cmd, ASCII text
opensnoop 通过跟踪 open() 系统调用来工作。为什么不使用 strace -feopen file 命令呢? 在这种情况下是可以的。然而,opensnoop 的一些优点在于它能在系统范围内工作,并且跟踪所有进程的 open() 系统调用。注意上例的输出中包括了从 systemd 打开的文件。opensnoop 应该系统开销更低:BPF 跟踪已经被优化过,而当前版本的 strace(1) 仍然使用较老和较慢的 ptrace(2) 接口。
3、 xfsslower
bcc/BPF 不仅仅可以分析系统调用。xfsslower 工具可以跟踪大于 1 毫秒(参数)延迟的常见 XFS 文件系统操作。
# /usr/share/bcc/tools/xfsslower 1
Tracing XFS operations slower than 1 ms
TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME
14:17:34 systemd-journa 530 S 0 0 1.69 system.journal
14:17:35 auditd 651 S 0 0 2.43 audit.log
14:17:42 cksum 4167 R 52976 0 1.04 at
14:17:45 cksum 4168 R 53264 0 1.62 [
14:17:45 cksum 4168 R 65536 0 1.01 certutil
14:17:45 cksum 4168 R 65536 0 1.01 dir
14:17:45 cksum 4168 R 65536 0 1.17 dirmngr-client
14:17:46 cksum 4168 R 65536 0 1.06 grub2-file
14:17:46 cksum 4168 R 65536 128 1.01 grub2-fstest
[...]
在上图输出中,我捕获到了多个延迟超过 1 毫秒 的 cksum(1) 读取操作(字段 “T” 等于 “R”)。这是在 xfsslower 工具运行的时候,通过在 XFS 中动态地检测内核函数实现的,并当它结束的时候解除该检测。这个 bcc 工具也有其它文件系统的版本:ext4slower、btrfsslower、zfsslower 和 nfsslower。
这是个有用的工具,也是 BPF 追踪的重要例子。对文件系统性能的传统分析主要集中在块 I/O 统计信息 —— 通常你看到的是由 iostat(1) 工具输出,并由许多性能监视 GUI 绘制的图表。这些统计数据显示的是磁盘如何执行,而不是真正的文件系统如何执行。通常比起磁盘来说,你更关心的是文件系统的性能,因为应用程序是在文件系统中发起请求和等待。并且,文件系统的性能可能与磁盘的性能大为不同!文件系统可以完全从内存缓存中读取数据,也可以通过预读算法和回写缓存来填充缓存。xfsslower 显示了文件系统的性能 —— 这是应用程序直接体验到的性能。通常这对于排除整个存储子系统的问题是有用的;如果确实没有文件系统延迟,那么性能问题很可能是在别处。
4、 biolatency
虽然文件系统性能对于理解应用程序性能非常重要,但研究磁盘性能也是有好处的。当各种缓存技巧都无法挽救其延迟时,磁盘的低性能终会影响应用程序。 磁盘性能也是容量规划研究的目标。
iostat(1) 工具显示了平均磁盘 I/O 延迟,但平均值可能会引起误解。 以直方图的形式研究 I/O 延迟的分布是有用的,这可以通过使用 [biolatency] 来实现18:
# /usr/share/bcc/tools/biolatency
Tracing block device I/O... Hit Ctrl-C to end.
^C
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 0 | |
32 -> 63 : 1 | |
64 -> 127 : 63 |**** |
128 -> 255 : 121 |********* |
256 -> 511 : 483 |************************************ |
512 -> 1023 : 532 |****************************************|
1024 -> 2047 : 117 |******** |
2048 -> 4095 : 8 | |
这是另一个有用的工具和例子;它使用一个名为 maps 的 BPF 特性,它可以用来实现高效的内核摘要统计。从内核层到用户层的数据传输仅仅是“计数”列。 用户级程序生成其余的。
值得注意的是,这种工具大多支持 CLI 选项和参数,如其使用信息所示:
# /usr/share/bcc/tools/biolatency -h
usage: biolatency [-h] [-T] [-Q] [-m] [-D] [interval] [count]
Summarize block device I/O latency as a histogram
positional arguments:
interval output interval, in seconds
count number of outputs
optional arguments:
-h, --help show this help message and exit
-T, --timestamp include timestamp on output
-Q, --queued include OS queued time in I/O time
-m, --milliseconds millisecond histogram
-D, --disks print a histogram per disk device
examples:
./biolatency # summarize block I/O latency as a histogram
./biolatency 1 10 # print 1 second summaries, 10 times
./biolatency -mT 1 # 1s summaries, milliseconds, and timestamps
./biolatency -Q # include OS queued time in I/O time
./biolatency -D # show each disk device separately
它们的行为就像其它 Unix 工具一样,以利于采用而设计。
5、 tcplife
另一个有用的工具是 tcplife ,该例显示 TCP 会话的生命周期和吞吐量统计。
# /usr/share/bcc/tools/tcplife
PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
12759 sshd 192.168.56.101 22 192.168.56.1 60639 2 3 1863.82
12783 sshd 192.168.56.101 22 192.168.56.1 60640 3 3 9174.53
12844 wget 10.0.2.15 34250 54.204.39.132 443 11 1870 5712.26
12851 curl 10.0.2.15 34252 54.204.39.132 443 0 74 505.90
在你说 “我不是可以只通过 tcpdump(8) 就能输出这个?” 之前请注意,运行 tcpdump(8) 或任何数据包嗅探器,在高数据包速率的系统上的开销会很大,即使 tcpdump(8) 的用户层和内核层机制已经过多年优化(要不可能更差)。tcplife 不会测试每个数据包;它只会有效地监视 TCP 会话状态的变化,并由此得到该会话的持续时间。它还使用已经跟踪了吞吐量的内核计数器,以及进程和命令信息(“PID” 和 “COMM” 列),这些对于 tcpdump(8) 等线上嗅探工具是做不到的。
6、 gethostlatency
之前的每个例子都涉及到内核跟踪,所以我至少需要一个用户级跟踪的例子。 这就是 gethostlatency,它检测用于名称解析的 gethostbyname(3) 和相关的库调用:
# /usr/share/bcc/tools/gethostlatency
TIME PID COMM LATms HOST
06:43:33 12903 curl 188.98 opensource.com
06:43:36 12905 curl 8.45 opensource.com
06:43:40 12907 curl 6.55 opensource.com
06:43:44 12911 curl 9.67 opensource.com
06:45:02 12948 curl 19.66 opensource.cats
06:45:06 12950 curl 18.37 opensource.cats
06:45:07 12952 curl 13.64 opensource.cats
06:45:19 13139 curl 13.10 opensource.cats
是的,总是有 DNS 请求,所以有一个工具来监视系统范围内的 DNS 请求会很方便(这只有在应用程序使用标准系统库时才有效)。看看我如何跟踪多个对 “opensource.com” 的查找? 第一个是 188.98 毫秒,然后更快,不到 10 毫秒,毫无疑问,这是缓存的作用。它还追踪多个对 “opensource.cats” 的查找,一个不存在的可怜主机名,但我们仍然可以检查第一个和后续查找的延迟。(第二次查找后是否有一些否定缓存的影响?)
7、 trace
好的,再举一个例子。 trace 工具由 Sasha Goldshtein 提供,并提供了一些基本的 printf(1) 功能和自定义探针。 例如:
# /usr/share/bcc/tools/trace 'pam:pam_start "%s: %s", arg1, arg2'
PID TID COMM FUNC -
13266 13266 sshd pam_start sshd: root
在这里,我正在跟踪 libpam 及其 pam_start(3) 函数,并将其两个参数都打印为字符串。 libpam 用于插入式身份验证模块系统,该输出显示 sshd 为 “root” 用户调用了 pam_start()(我登录了)。 其使用信息中有更多的例子(trace -h),而且所有这些工具在 bcc 版本库中都有手册页和示例文件。 例如 trace_example.txt 和 trace.8。
通过包安装 bcc
安装 bcc 最佳的方法是从 iovisor 仓储库中安装,按照 bcc 的 INSTALL.md 中找到文档和更新说明。 我在 Fedora 26 上做了如下的事情:
sudo dnf install -y bison cmake ethtool flex git iperf libstdc++-static
python-netaddr python-pip gcc gcc-c++ make zlib-devel
elfutils-libelf-devel
sudo dnf install -y luajit luajit-devel # for Lua support
sudo dnf install -y
http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm
sudo pip install pyroute2
sudo dnf install -y clang clang-devel llvm llvm-devel llvm-static ncurses-devel
除 netperf 外一切妥当,其中有以下错误:
Curl error (28): Timeout was reached for http://pkgs.repoforge.org/netperf/netperf-2.6.0-1.el6.rf.x86_64.rpm [Connection timed out after 120002 milliseconds]
不必理会,netperf 是可选的,它只是用于测试,而 bcc 没有它也会编译成功。
以下是余下的 bcc 编译和安装步骤:
git clone https://github.com/iovisor/bcc.git
mkdir bcc/build; cd bcc/build
cmake .. -DCMAKE_INSTALL_PREFIX=/usr
make
sudo make install
现在,命令应该可以工作了:
# /usr/share/bcc/tools/opensnoop
PID COMM FD ERR PATH
4131 date 3 0 /etc/ld.so.cache
4131 date 3 0 /lib64/libc.so.6
4131 date 3 0 /usr/lib/locale/locale-archive
4131 date 3 0 /etc/localtime
[...]
写在最后和其他的前端
这是一个可以在 Fedora 和 Red Hat 系列操作系统上使用的新 BPF 性能分析强大功能的快速浏览。我演示了 BPF 的流行前端 bcc ,并包括了其在 Fedora 上的安装说明。bcc 附带了 60 多个用于性能分析的新工具,这将帮助您充分利用 Linux 系统。也许你会直接通过 SSH 使用这些工具,或者一旦 GUI 监控程序支持 BPF 的话,你也可以通过它们来使用相同的功能。
此外,bcc 并不是正在开发的唯一前端。ply 和 bpftrace,旨在为快速编写自定义工具提供更高级的语言支持。此外,SystemTap 刚刚发布版本 3.2,包括一个早期的实验性 eBPF 后端。 如果这个继续开发,它将为运行多年来开发的许多 SystemTap 脚本和 tapset(库)提供一个安全和高效的生产级引擎。(随同 eBPF 使用 SystemTap 将是另一篇文章的主题。)
如果您需要开发自定义工具,那么也可以使用 bcc 来实现,尽管语言比 SystemTap、ply 或 bpftrace 要冗长得多。我的 bcc 工具可以作为代码示例,另外我还贡献了用 Python 开发 bcc 工具的教程。 我建议先学习 bcc 的 multi-tools,因为在需要编写新工具之前,你可能会从里面获得很多经验。 您可以从它们的 bcc 存储库funccount,funclatency,funcslower,stackcount,trace ,argdist 的示例文件中研究 bcc。
感谢 Opensource.com 进行编辑。
关于作者
Brendan Gregg 是 Netflix 的一名高级性能架构师,在那里他进行大规模的计算机性能设计、分析和调优。
via:https://opensource.com/article/17/11/bccbpf-performance
作者:Brendan Gregg 译者:yongshouzhang 校对:wxy
发表回复