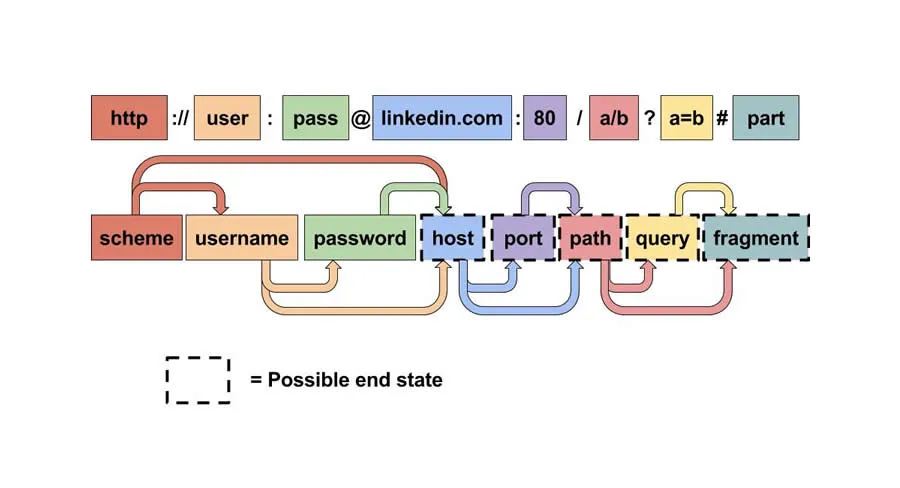
Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数。
解析url
urlparse() 函数可以将 URL 解析成 ParseResult 对象。对象中包含了六个元素,分别为:
- 协议(scheme)
- 域名(netloc)
- 路径(path)
- 路径参数(params)
- 查询参数(query)
- 片段(fragment)
from urllib.parse import urlparse
url='http://user:pwd@domain:80/path;params?query=queryarg#fragment'
parsed_result=urlparse(url)
print('parsed_result 包含了',len(parsed_result),'个元素')
print(parsed_result)结果为:
parsed_result 包含了 6 个元素
ParseResult(scheme='http', netloc='user:pwd@domain:80', path='/path', params='params', query='query=queryarg', fragment='fragment')
ParseResult 继承于 namedtuple,因此可以同时通过索引和命名属性来获取 URL 中各部分的值。
为了方便起见, ParseResult 还提供了 username、 password、 hostname、 port 对 netloc 进一步进行拆分。
print('scheme :', parsed_result.scheme)
print('netloc :', parsed_result.netloc)
print('path :', parsed_result.path)
print('params :', parsed_result.params)
print('query :', parsed_result.query)
print('fragment:', parsed_result.fragment)
print('username:', parsed_result.username)
print('password:', parsed_result.password)
print('hostname:', parsed_result.hostname)
print('port :', parsed_result.port)结果为:
scheme : http
netloc : user:pwd@domain:80
path : /path
params : params
query : query=queryarg
fragment: fragment
username: user
password: pwd
hostname: domain
port : 80
除了 urlparse() 之外,还有一个类似的 urlsplit() 函数也能对 URL 进行拆分,所不同的是, urlsplit() 并不会把 路径参数(params) 从 路径(path) 中分离出来。
当 URL 中路径部分包含多个参数时,使用 urlparse() 解析是有问题的:
url='http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment'
parsed_result=urlparse(url)
print(parsed_result)
print('parsed.path :', parsed_result.path)
print('parsed.params :', parsed_result.params)结果为:
ParseResult(scheme='http', netloc='user:pwd@domain:80', path='/path1;params1/path2', params='params2', query='query=queryarg', fragment='fragment')
parsed.path : /path1;params1/path2
parsed.params : params2
这时可以使用 urlsplit() 来解析:
from urllib.parse import urlsplit
split_result=urlsplit(url)
print(split_result)
print('split.path :', split_result.path)
# SplitResult 没有 params 属性结果为:
SplitResult(scheme='http', netloc='user:pwd@domain:80', path='/path1;params1/path2;params2', query='query=queryarg', fragment='fragment')
split.path : /path1;params1/path2;params2
若只是要将 URL 后的 fragment 标识拆分出来,可以使用 urldefrag() 函数:
from urllib.parse import urldefrag
url = 'http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment'
d = urldefrag(url)
print(d)
print('url :', d.url)
print('fragment:', d.fragment)结果为:
DefragResult(url='http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg', fragment='fragment')
url : http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg
fragment: fragment
组建URL
ParsedResult 对象和 SplitResult 对象都有一个 geturl() 方法,可以返回一个完整的 URL 字符串。
print(parsed_result.geturl())
print(split_result.geturl())结果为:
http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment
http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment
但是 geturl() 只在 ParsedResult 和 SplitResult 对象中有,若想将一个普通的元组组成 URL,则需要使用 urlunparse() 函数:
from urllib.parse import urlunparse
url_compos = ('http', 'user:pwd@domain:80', '/path1;params1/path2', 'params2', 'query=queryarg', 'fragment')
print(urlunparse(url_compos))结果为:
http://user:pwd@domain:80/path1;params1/path2;params2?query=queryarg#fragment
相对路径转换绝对路径
除此之外,urllib.parse 还提供了一个 urljoin() 函数,来将相对路径转换成绝对路径的 URL。
from urllib.parse import urljoin
print(urljoin('http://www.example.com/path/file.html', 'anotherfile.html'))
print(urljoin('http://www.example.com/path/', 'anotherfile.html'))
print(urljoin('http://www.example.com/path/file.html', '../anotherfile.html'))
print(urljoin('http://www.example.com/path/file.html', '/anotherfile.html'))结果为:
http://www.example.com/path/anotherfile.html
http://www.example.com/path/anotherfile.html
http://www.example.com/anotherfile.html
http://www.example.com/anotherfile.html
查询参数的构造和解析
使用 urlencode() 函数可以将一个 dict 转换成合法的查询参数:
from urllib.parse import urlencode
query_args = {
'name': 'dark sun',
'country': '中国'
}
query_args = urlencode(query_args)
print(query_args)结果为:
name=dark+sun&country=%E4%B8%AD%E5%9B%BD
可以看到特殊字符也被正确地转义了。
相对的,可以使用 parse_qs() 来将查询参数解析成 dict。
from urllib.parse import parse_qs
print(parse_qs(query_args))结果为:
{'name': ['dark sun'], 'country': ['中国']}
如果只是希望对特殊字符进行转义,那么可以使用 quote 或 quote_plus 函数,其中 quote_plus 比 quote 更激进一些,会把 :、/ 一类的符号也给转义了。
from urllib.parse import quote, quote_plus, urlencode
url = 'http://localhost:1080/~hello!/'
print('urlencode :', urlencode({'url': url}))
print('quote :', quote(url))
print('quote_plus:', quote_plus(url))结果为:
urlencode : url=http%3A%2F%2Flocalhost%3A1080%2F%7Ehello%21%2F
quote : http%3A//localhost%3A1080/%7Ehello%21/
quote_plus: http%3A%2F%2Flocalhost%3A1080%2F%7Ehello%21%2F
可以看到 urlencode 中应该是调用 quote_plus 来进行转义的。
逆向操作则使用 unquote 或 unquote_plus 函数:
from urllib.parse import unquote, unquote_plus
encoded_url = 'http%3A%2F%2Flocalhost%3A1080%2F%7Ehello%21%2F'
print(unquote(encoded_url))
print(unquote_plus(encoded_url))结果为:
http://localhost:1080/~hello!/
http://localhost:1080/~hello!/
你会发现 unquote 函数居然能正确地将 quote_plus 的结果转换回来。
发表回复