简介
伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
我将基于 Kubernetes 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
我将聚焦 Kubernetes 及其部署。
让我们开始吧。
应用
TL;DR
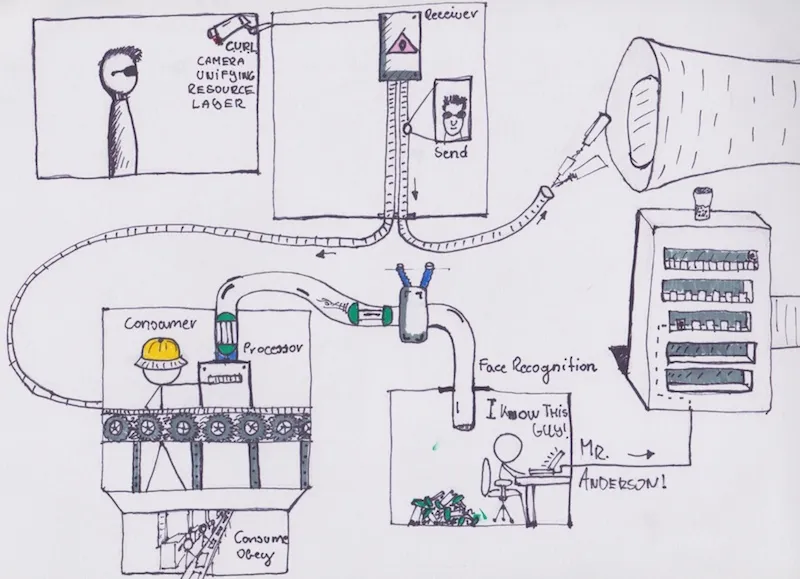
该应用本身由 6 个组件构成。代码可以从如下链接中找到:Kubenetes 集群示例。
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 接收器 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 NSQ 建立队列。
图片处理 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 gRPC 将图片路径发送至 Python 编写的 人脸识别 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
标记为失败的图片可以通过计划任务等方式进行重试。
那么具体是如何工作的呢?我们深入探索一下。
接收器
接收器服务是整个流程的起点,通过如下形式的 API 接收请求:
curl -d '{"path":"/unknown_images/unknown0001.webp"}' http://127.0.0.1:8000/image/post
此时,接收器将 路径 存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“ 实体对象 的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
图片处理器
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go 协程 ,具体为:
Consume
这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 sync.Condition。
ProcessImages
该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
- 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
- 从数据库获取图片对应的实体
- 为 断路器 准备两个函数
- 函数 1: 用于 RPC 方法调用的主函数
- 函数 2: 基于 ping 的断路器健康检查
- 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
- 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
- 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
- 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
这个服务可以复制多份同时运行。
断路器
即使对于一个复制资源几乎没有开销的系统,也会有意外的情况发生,例如网络故障或任何两个服务之间的通信存在问题等。我在 gRPC 调用中实现了一个简单的断路器,这十分有趣。
下面给出工作原理:
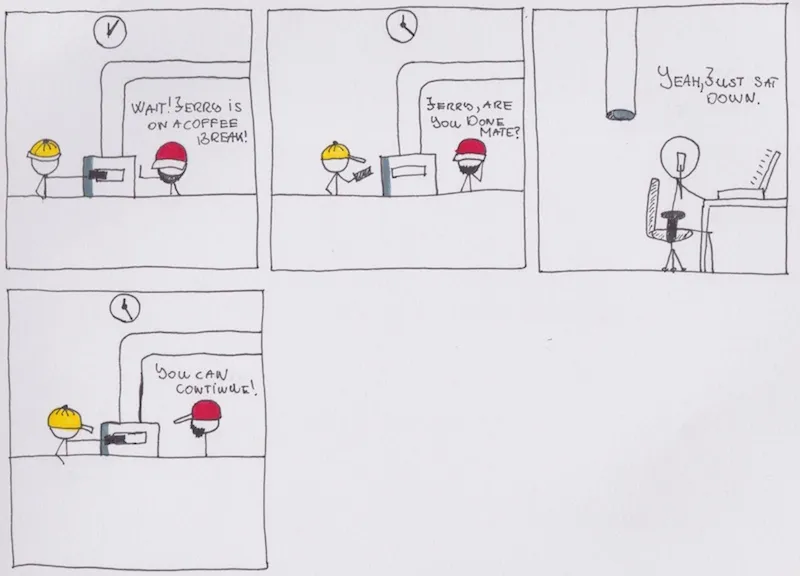
当出现 5 次不成功的服务调用时,断路器启动并阻断后续的调用请求。经过指定的时间后,它对服务进行健康检查并判断是否恢复。如果问题依然存在,等待时间会进一步增大。如果已经恢复,断路器停止对服务调用的阻断,允许请求流量通过。
前端
前端只包含一个极其简单的表格视图,通过 Go 自身的 html/模板显示一系列图片。
人脸识别
人脸识别是整个识别的关键点。仅因为追求灵活性,我将这个服务设计为基于 gRPC 的服务。最初我使用 Go 编写,但后续发现基于 Python 的实现更加适合。事实上,不算 gRPC 部分的代码,人脸识别部分仅有 7 行代码。我使用的人脸识别库极为出色,它包含 OpenCV 的全部 C 绑定。维护 API 标准意味着只要标准本身不变,实现可以任意改变。
注意:我曾经试图使用 GoCV,这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 hannibal_1.webp、 hannibal_2.webp、 gergely_1.webp、 john_doe.webp。在数据库中,我使用两个表记录信息,分别为 person、 person_images,具体如下:
+-+
| id | name |
+-+
| 1 | Gergely |
| 2 | John Doe |
| 3 | Hannibal |
+-+
+-+-+--+
| 1 | hannibal_1.webp | 3 |
| 2 | hannibal_2.webp | 3 |
+-+-
Pods 和 服务概览:

### MySQL
第一个要部署的服务是数据库。
按照 Kubernetes 的示例 [Kubenetes MySQL](https://kubernetes.io/docs/tasks/run-application/run-single-instance-stateful-application/#deploy-mysql) 进行部署,即可以满足我的需求。注意:示例配置文件的 MYSQL_PASSWORD 字段使用了明文密码,我将使用 [Kubernetes Secrets](https://kubernetes.io/docs/concepts/configuration/secret/) 对象以提高安全性。
我创建了一个 Secret 对象,对应的本地 yaml 文件如下:
apiVersion: v1
kind: Secret
metadata:
name: kube-face-secret
type: Opaque
data:
mysql_password: base64codehere
mysql_userpassword: base64codehere
其中 base64 编码通过如下命令生成:
echo -n “ubersecurepassword” | base64
echo -n “root:ubersecurepassword” | base64
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 `mysql_password`,仅包含密码;另一条对应 `mysql_userpassword`,包含用户和密码。后文会用到 `mysql_userpassword`,但没有提及相应的生成)
我的部署 yaml 对应部分如下:
…
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_password
…
另外值得一提的是,我使用卷将数据库持久化,卷对应的定义如下:
…
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
…
volumes:- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
…
- name: mysql-persistent-storage
其中 `presistentVolumeClain` 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:[Kubernetes 持久化存储](https://kubernetes.io/docs/concepts/storage/persistent-volumes)。
(LCTT 译注:使用 `presistentVolumeClain` 之前需要创建 `presistentVolume`,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
使用如下命令部署 MySQL 服务:
kubectl apply -f mysql.yaml
这里比较一下 `create` 和 `apply`。`apply` 是一种<ruby> 宣告式 <rt> declarative </rt></ruby>的对象配置命令,而 `create` 是<ruby> 命令式 <rt> imperative </rt> 的命令。当下我们需要知道的是, <code> create </code> 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 <code> apply </code> 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 <code> mysql </code> 的服务,当我执行 <code> apply -f mysql.yaml </code> 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 <code> create </code> ,Kubernetes 会报错,告知服务已经创建。</ruby>
想了解更多信息,请阅读如下文档:[Kubernetes 对象管理](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/overview/),[命令式配置](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/imperative-config/)和[宣告式配置](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/declarative-config/)。
运行如下命令查看执行进度信息:
描述完整信息
kubectl describe deployment mysql
仅描述 Pods 信息
kubectl get pods -l app=mysql
(第一个命令)输出示例如下:
…
Type Status Reason
-+
| Tables_in_kube |
+-+
3 rows in set (0.00 sec)
mysql>
(LCTT 译注:上述代码块中的第一行是作者执行命令所在路径,执行第二行的命令无需在该目录中进行)
上述操作完成了数据库服务的初始化。使用如下命令可以查看服务日志:
kubectl logs deployment/mysql -f
### NSQ 查询
NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这里使用 `clusterIP: None` 在 Kubernetes 中将其设置为<ruby> 无头服务 <rt> headless service </rt></ruby>,意味着该服务不使用负载均衡模式,也不使用单独的服务 IP。DNS 将基于服务<ruby> 选择器 <rt> selectors </rt></ruby>。
我们的 NSQ 查询服务对应的选择器为:
selector:
matchLabels:
app: nsqlookup
那么,内部 DNS 对应的实体类似于:`nsqlookup.default.svc.cluster.local`。
无头服务的更多细节,可以参考:[无头服务](https://kubernetes.io/docs/concepts/services-networking/service/#headless-services)。
NSQ 服务与 MySQL 服务大同小异,只需要少许修改即可。如前所述,我将使用 NSQ 原生的 Docker 镜像,名称为 `nsqio/nsq`。镜像包含了全部的 nsq 命令,故 nsqd 也将使用该镜像,只是使用的命令不同。对于 nsqlookupd,命令如下:
command: [“/nsqlookupd”]
args: [“–broadcast-address=nsqlookup.default.svc.cluster.local”]
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,`nsqlookup` 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
容器模板:
ports:
- containerPort: 4160
hostPort: 4160
- containerPort: 4161
hostPort: 4161
服务模板:
spec:
ports:
- name: main
protocol: TCP
port: 4160
targetPort: 4160 - name: secondary
protocol: TCP
port: 4161
targetPort: 4161
端口名称是必须的,Kubernetes 基于名称进行区分。(LCTT 译注:端口名更新为作者 GitHub 对应文件中的名称)
像之前那样,使用如下命令创建服务:
kubectl apply -f nsqlookup.yaml
nsqlookupd 部分到此结束。截至目前,我们已经准备好两个主要的组件。
### 接收器
这部分略微复杂。接收器需要完成三项工作:
* 创建一些部署
* 创建 nsq 守护进程
* 将本服务对外公开
#### 部署
第一个要创建的部署是接收器本身,容器镜像为 `skarlso/kube-receiver-alpine`。
#### NSQ 守护进程
接收器需要使用 NSQ 守护进程。如前所述,接收器在其内部运行一个 NSQ,这样与 nsq 的通信可以在本地进行,无需通过网络。为了让接收器可以这样操作,NSQ 需要与接收器部署在同一个节点上。
NSQ 守护进程也需要一些调整的参数配置:
ports:
- containerPort: 4150
hostPort: 4150
- containerPort: 4151
hostPort: 4151
env:
- name: NSQLOOKUP_ADDRESS
value: nsqlookup.default.svc.cluster.local
- name: NSQ_BROADCAST_ADDRESS
value: nsqd.default.svc.cluster.local
command: ["/nsqd"]
args: ["--lookupd-tcp-address=$(NSQLOOKUP_ADDRESS):4160", "--broadcast-address=$(NSQ_BROADCAST_ADDRESS)"]
其中我们配置了 `lookup-tcp-address` 和 `broadcast-address` 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
#### 对外公开
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
但由于我使用的本地集群只有一个节点,那么使用 `NodePort` 的方式就足够了。`NodePort` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
更多信息,请参考文档:[服务发布](https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-processor-deployment
spec:
selector:
matchLabels:
app: image-processor
replicas: 1
template:
metadata:
labels:
app: image-processor
spec:
containers:
- name: image-processor
image: skarlso/kube-processor-alpine:latest
env:
- name: MYSQL_CONNECTION
value: "mysql.default.svc.cluster.local"
- name: MYSQL_USERPASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_userpassword
- name: MYSQL_PORT
# TIL: If this is 3306 without " kubectl throws an error.
value: "3306"
- name: MYSQL_DBNAME
value: kube
- name: NSQ_LOOKUP_ADDRESS
value: "nsqlookup.default.svc.cluster.local:4161"
- name: GRPC_ADDRESS
value: "face-recog.default.svc.cluster.local:50051"
文件中唯一需要提到的是用于配置应用的多个环境变量属性,主要关注 nsqlookupd 地址 和 gRPC 地址。
运行如下命令完成部署:
kubectl apply -f image_processor.yaml
人脸识别
人脸识别服务的确包含一个 Kubernetes 服务,具体而言是一个比较简单、仅供图片处理器使用的服务。模板如下:
apiVersion: v1
kind: Service
metadata:
name: face-recog
spec:
ports:
- protocol: TCP
port: 50051
targetPort: 50051
selector:
app: face-recog
clusterIP: None
更有趣的是,该服务涉及两个卷,分别为 known_people 和 unknown_people。你能猜到卷中包含什么内容吗?对,是图片。known_people 卷包含所有新图片,接收器收到图片后将图片发送至该卷对应的路径,即挂载点。在本例中,挂载点为 /unknown_people,人脸识别服务需要能够访问该路径。
对于 Kubernetes 和 Docker 而言,这很容易。卷可以使用挂载的 S3 或 某种 nfs,也可以是宿主机到虚拟机的本地挂载。可选方式有很多 (至少有一打那么多)。为简洁起见,我将使用本地挂载方式。
挂载卷分为两步。第一步,需要在 Dockerfile 中指定卷:
VOLUME [ "/unknown_people", "/known_people" ]
第二步,就像之前为 MySQL Pod 挂载卷那样,需要在 Kubernetes 模板中配置;相比而言,这里使用 hostPath,而不是 MySQL 例子中的 PersistentVolumeClaim:
volumeMounts:
- name: known-people-storage
mountPath: /known_people
- name: unknown-people-storage
mountPath: /unknown_people
volumes:
- name: known-people-storage
hostPath:
path: /Users/hannibal/Temp/known_people
type: Directory
- name: unknown-people-storage
hostPath:
path: /Users/hannibal/Temp/
type: Directory
(LCTT 译注:对于多节点模式,由于人脸识别服务和接收器服务可能不在一个节点上,故需要使用共享存储而不是节点本地存储。另外,出于 Python 代码的逻辑,推荐保持两个文件夹的嵌套结构,即 known_people 作为子目录。)
我们还需要为 known_people 文件夹做配置设置,用于人脸识别程序。当然,使用环境变量属性可以完成该设置:
env:
- name: KNOWN_PEOPLE
value: "/known_people"
Python 代码按如下方式搜索图片:
known_people = os.getenv('KNOWN_PEOPLE', 'known_people')
print("Known people images location is: %s" % known_people)
images = self.image_files_in_folder(known_people)
其中 image_files_in_folder 函数定义如下:
def image_files_in_folder(self, folder):
return [os.path.join(folder, f) for f in os.listdir(folder) if re.match(r'.*.(jpg|jpeg|png)', f, flags=re.I)]
看起来不错。
如果接收器现在收到一个类似下面的请求(接收器会后续将其发送出去):
curl -d '{"path":"/unknown_people/unknown220.webp"}' http://192.168.99.100:30251/image/post
图像处理器会在 /unknown_people 目录搜索名为 unknown220.webp 的图片,接着在 known_folder 文件中找到 unknown220.webp 对应个人的图片,最后返回匹配图片的名称。
查看日志,大致信息如下:
# 接收器
❯ curl -d '{"path":"/unknown_people/unknown219.webp"}' http://192.168.99.100:30251/image/post
got path: {Path:/unknown_people/unknown219.webp}
image saved with id: 4
image sent to nsq
# 图片处理器
2018/03/26 18:11:21 INF 1 [images/ch] querying nsqlookupd http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images
2018/03/26 18:11:59 Got a message: 4
2018/03/26 18:11:59 Processing image id: 4
2018/03/26 18:12:00 got person: Hannibal
2018/03/26 18:12:00 updating record with person id
2018/03/26 18:12:00 done
我们已经使用 Kubernetes 部署了应用正常工作所需的全部服务。
前端
更进一步,可以使用简易的 Web 应用更好的显示数据库中的信息。这也是一个对外公开的服务,使用的参数可以参考接收器。
部署后效果如下:

回顾
到目前为止我们做了哪些操作呢?我一直在部署服务,用到的命令汇总如下:
kubectl apply -f mysql.yaml
kubectl apply -f nsqlookup.yaml
kubectl apply -f receiver.yaml
kubectl apply -f image_processor.yaml
kubectl apply -f face_recognition.yaml
kubectl apply -f frontend.yaml
命令顺序可以打乱,因为除了图片处理器的 NSQ 消费者外的应用在启动时并不会建立连接,而且图片处理器的 NSQ 消费者会不断重试。
使用 kubectl get pods 查询正在运行的 Pods,示例如下:
❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
face-recog-6bf449c6f-qg5tr 1/1 Running 0 1m
image-processor-deployment-6467468c9d-cvx6m 1/1 Running 0 31s
mysql-7d667c75f4-bwghw 1/1 Running 0 36s
nsqd-584954c44c-299dz 1/1 Running 0 26s
nsqlookup-7f5bdfcb87-jkdl7 1/1 Running 0 11s
receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
运行 minikube service list:
❯ minikube service list
|-|--|
| NAMESPACE | NAME | URL |
|-|--|
| default | face-recog | No node port |
| default | kubernetes | No node port |
| default | mysql | No node port |
| default | nsqd | No node port |
| default | nsqlookup | No node port |
| default | receiver-service | http://192.168.99.100:30251 |
| kube-system | kube-dns | No node port |
| kube-system | kubernetes-dashboard | http://192.168.99.100:30000 |
|-|--|
滚动更新
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
发表回复