
使用 Python behave 框架的行为驱动开发模式可以帮助你的团队更好的协作和测试自动化。

您是否听说过 行为驱动开发 (BDD),并好奇这是个什么东西?也许你发现了团队成员在谈论“嫩瓜”(LCTT 译注:“ 嫩瓜 ” 是一种简单的英语文本语言,工具 cucumber 通过解释它来执行测试脚本,见下文),而你却不知所云。或许你是一个 Python 人 ,正在寻找更好的方法来测试你的代码。 无论在什么情况下,了解 BDD 都可以帮助您和您的团队实现更好的协作和测试自动化,而 Python 的 behave 框架是一个很好的起点。
什么是 BDD?
在软件中,行为是指在明确定义的输入、动作和结果场景中功能是如何运转的。 产品可以表现出无数的行为,例如:
- 在网站上提交表单
- 搜索想要的结果
- 保存文档
- 进行 REST API 调用
- 运行命令行界面命令
根据产品的行为定义产品的功能可以更容易地描述产品,并对其进行开发和测试。 BDD 的核心是:使行为成为软件开发的焦点。在开发早期使用示例语言的规范来定义行为。最常见的行为规范语言之一是 Gherkin,Cucumber项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
下面是用Gherkin编写的行为规范的示例:
根据产品的行为定义产品的功能可以更容易地描述产品,开发产品并对其进行测试。 这是BDD的核心:使行为成为软件开发的焦点。 在开发早期使用示例规范的语言来定义行为。 最常见的行为规范语言之一是Gherkin,来自 Cucumber 项目中的 Given-When-Then 场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和聚焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
下面是用 Gherkin 编写的行为规范的示例:
Scenario: Basic DuckDuckGo Search
Given the DuckDuckGo home page is displayed
When the user searches for "panda"
Then results are shown for "panda"快速浏览一下,行为是直观易懂的。 除少数关键字外,该语言为自由格式。 场景简洁而有意义。 一个真实的例子说明了这种行为。 步骤以声明的方式表明应该发生什么——而不会陷入如何如何的细节中。
BDD 的主要优点是良好的协作和自动化。 每个人都可以为行为开发做出贡献,而不仅仅是程序员。从流程开始就定义并理解预期的行为。测试可以与它们涵盖的功能一起自动化。每个测试都包含一个单一的、独特的行为,以避免重复。最后,现有的步骤可以通过新的行为规范重用,从而产生雪球效果。
Python 的 behave 框架
behave 是 Python 中最流行的 BDD 框架之一。 它与其他基于 Gherkin 的 Cucumber 框架非常相似,尽管没有得到官方的 Cucumber 定名。 behave 有两个主要层:
- 用 Gherkin 的
.feature文件编写的行为规范 - 用 Python 模块编写的步骤定义和钩子,用于实现 Gherkin 步骤
如上例所示,Gherkin 场景有三部分格式:
- 鉴于(Given)一些初始状态
- 每当(When)行为发生时
- 然后(Then)验证结果
当 behave 运行测试时,每个步骤由装饰器“粘合”到 Python 函数。
安装
作为先决条件,请确保在你的计算机上安装了 Python 和 pip。 我强烈建议使用 Python 3.(我还建议使用 pipenv,但以下示例命令使用更基本的 pip。)
behave 框架只需要一个包:
pip install behave其他包也可能有用,例如:
pip install requests # 用于调用 REST API
pip install selenium # 用于 web 浏览器交互GitHub 上的 behavior-driven-Python 项目包含本文中使用的示例。
Gherkin 特点
behave 框架使用的 Gherkin 语法实际上是符合官方的 Cucumber Gherkin 标准的。.feature 文件包含了功能(Feature)部分,而场景部分又包含具有 Given-When-Then 步骤的场景(Scenario) 部分。 以下是一个例子:
Feature: Cucumber Basket
As a gardener,
I want to carry many cucumbers in a basket,
So that I don’t drop them all.
@cucumber-basket
Scenario: Add and remove cucumbers
Given the basket is empty
When "4" cucumbers are added to the basket
And "6" more cucumbers are added to the basket
But "3" cucumbers are removed from the basket
Then the basket contains "7" cucumbers这里有一些重要的事情需要注意:
Feature和Scenario部分都有简短的描述性标题。- 紧跟在
Feature标题后面的行是会被 behave 框架忽略掉的注释。将功能描述放在那里是一种很好的做法。 Scenario和Feature可以有标签(注意@cucumber-basket标记)用于钩子和过滤(如下所述)。- 步骤都遵循严格的 Given-When-Then 顺序。
- 使用
And和But可以为任何类型添加附加步骤。 - 可以使用输入对步骤进行参数化——注意双引号里的值。
通过使用场景大纲(Scenario Outline),场景也可以写为具有多个输入组合的模板:
Feature: Cucumber Basket
@cucumber-basket
Scenario Outline: Add cucumbers
Given the basket has “<initial>” cucumbers
When "<more>" cucumbers are added to the basket
Then the basket contains "<total>" cucumbers
Examples: Cucumber Counts
| initial | more | total |
| 0 | 1 | 1 |
| 1 | 2 | 3 |
| 5 | 4 | 9 |场景大纲总是有一个示例(Examples)表,其中第一行给出列标题,后续每一行给出一个输入组合。 只要列标题出现在由尖括号括起的步骤中,行值就会被替换。 在上面的示例中,场景将运行三次,因为有三行输入组合。 场景大纲是避免重复场景的好方法。
Gherkin 语言还有其他元素,但这些是主要的机制。 想了解更多信息,请阅读 Automation Panda 这个网站的文章 Gherkin by Example 和 Writing Good Gherkin。
Python 机制
每个 Gherkin 步骤必须“粘合”到步骤定义——即提供了实现的 Python 函数。 每个函数都有一个带有匹配字符串的步骤类型装饰器。它还接收共享的上下文和任何步骤参数。功能文件必须放在名为 features/ 的目录中,而步骤定义模块必须放在名为 features/steps/ 的目录中。 任何功能文件都可以使用任何模块中的步骤定义——它们不需要具有相同的名称。 下面是一个示例 Python 模块,其中包含 cucumber basket 功能的步骤定义。
from behave import *
from cucumbers.basket import CucumberBasket
@given('the basket has "{initial:d}" cucumbers')
def step_impl(context, initial):
context.basket = CucumberBasket(initial_count=initial)
@when('"{some:d}" cucumbers are added to the basket')
def step_impl(context, some):
context.basket.add(some)
@then('the basket contains "{total:d}" cucumbers')
def step_impl(context, total):
assert context.basket.count == total可以使用三个步骤匹配器:parse、cfparse 和 re。默认的,也是最简单的匹配器是 parse,如上例所示。注意如何解析参数化值并将其作为输入参数传递给函数。一个常见的最佳实践是在步骤中给参数加双引号。
每个步骤定义函数还接收一个上下文变量,该变量保存当前正在运行的场景的数据,例如 feature、scenario 和 tags 字段。也可以添加自定义字段,用于在步骤之间共享数据。始终使用上下文来共享数据——永远不要使用全局变量!
behave 框架还支持钩子来处理 Gherkin 步骤之外的自动化问题。钩子是一个将在步骤、场景、功能或整个测试套件之前或之后运行的功能。钩子让人联想到面向方面的编程。它们应放在 features/ 目录下的特殊 environment.py 文件中。钩子函数也可以检查当前场景的标签,因此可以有选择地应用逻辑。下面的示例显示了如何使用钩子为标记为 @web 的任何场景生成和销毁一个 Selenium WebDriver 实例。
from selenium import webdriver
def before_scenario(context, scenario):
if 'web' in context.tags:
context.browser = webdriver.Firefox()
context.browser.implicitly_wait(10)
def after_scenario(context, scenario):
if 'web' in context.tags:
context.browser.quit()注意:也可以使用 fixtures 进行构建和清理。
要了解一个 behave 项目应该是什么样子,这里是示例项目的目录结构:
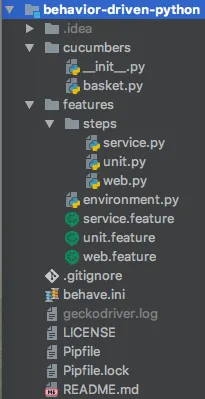
任何 Python 包和自定义模块都可以与 behave 框架一起使用。 使用良好的设计模式构建可扩展的测试自动化解决方案。步骤定义代码应简明扼要。
运行测试
要从命令行运行测试,请切换到项目的根目录并运行 behave 命令。 使用 -help 选项查看所有可用选项。
以下是一些常见用例:
# run all tests
behave
# run the scenarios in a feature file
behave features/web.feature
# run all tests that have the @duckduckgo tag
behave --tags @duckduckgo
# run all tests that do not have the @unit tag
behave --tags ~@unit
# run all tests that have @basket and either @add or @remove
behave --tags @basket --tags @add,@remove为方便起见,选项可以保存在 config 文件中。
其他选择
behave 不是 Python 中唯一的 BDD 测试框架。其他好的框架包括:
- pytest-bdd,是 pytest 的插件,和 behave 一样,它使用 Gherkin 功能文件和步骤定义模块,但它也利用了 pytest 的所有功能和插件。例如,它可以使用 pytest-xdist 并行运行 Gherkin 场景。 BDD 和非 BDD 测试也可以与相同的过滤器一起执行。pytest-bdd 还提供更灵活的目录布局。
- radish 是一个 “Gherkin 增强版”框架——它将场景循环和前提条件添加到标准的 Gherkin 语言中,这使得它对程序员更友好。它还像 behave 一样提供了丰富的命令行选项。
- lettuce 是一种较旧的 BDD 框架,与 behave 非常相似,在框架机制方面存在细微差别。然而,GitHub 最近显示该项目的活动很少(截至2018 年 5 月)。
任何这些框架都是不错的选择。
另外,请记住,Python 测试框架可用于任何黑盒测试,即使对于非 Python 产品也是如此! BDD 框架非常适合 Web 和服务测试,因为它们的测试是声明性的,而 Python 是一种很好的测试自动化语言。
本文基于作者的 PyCon Cleveland 2018 演讲“行为驱动的Python”。
via: https://opensource.com/article/18/5/behavior-driven-python
作者:Andrew Knight 选题:lujun9972 译者:Flowsnow 校对:wxy
发表回复